
Padrões de design para garantir agentes LLM contra injeções rápidas
Padrões de design para garantir agentes LLM contra injeções rápidas
13 de junho de 2025
Este novo artigo de 11 autores de organizações como IBM, Laboratórios Invariantes, ETH Zurique, Google e Microsoft é um excelente Além da literatura sobre injeção imediata e segurança LLM.
Neste trabalho, descrevemos um número de Padrões de design Para agentes LLM que mitigam significativamente o risco de injeções rápidas. Esses padrões de design restringem as ações dos agentes para impedir explicitamente de resolver arbitrário tarefas. Acreditamos que esses padrões de design oferecem uma troca valiosa entre a utilidade e a segurança dos agentes.
Aqui está a citação completa: Padrões de design para garantir agentes LLM contra injeções rápidas (2025). Volhejn.
Estou tão animado para ver papéis como este começando a aparecer. Eu escrevi sobre o Google DeepMind’s Derrotar injeções rápidas por design Artigo (também conhecido como The Camel Paper) em abril, que foi o primeiro artigo que eu vi que propôs uma solução credível para alguns dos desafios colocados pela rápida injeção contra sistemas LLM de uso de ferramentas (geralmente chamados de “agentes”).
Este novo artigo fornece uma explicação robusta de injeção imediata e propõe seis padrões de projeto para ajudar a proteger contra ele, incluindo o padrão proposto pelo papel de camelo.
O escopo do problema
Os autores deste artigo muito claramente Entenda o escopo do problema:
Enquanto os agentes e suas defesas dependem da classe atual de modelos de idiomas, Acreditamos que é improvável que os agentes de uso geral possam fornecer garantias de segurança significativas e confiáveis.
Isso leva a uma pergunta mais produtiva: Que tipos de agentes podemos construir hoje que produzem trabalho útil e oferecem resistência para solicitar ataques de injeção? Nesta seção, introduzimos um conjunto de padrões de design para agentes LLM que visam mitigar – se não forem totalmente eliminados – o risco de ataques rápidos de injeção. Esses padrões impõem restrições intencionais aos agentes, limitando explicitamente sua capacidade de executar arbitrário tarefas.
Esta é uma abordagem muito realista. Não temos uma solução mágica para solicitar injeção, por isso precisamos fazer trocas. A troca que eles fazem aqui é “limitar a capacidade dos agentes de executar tarefas arbitrárias”. Isso não é uma troca popular, mas dá a este artigo muita credibilidade nos meus olhos.
Este parágrafo prova que eles recebem completamente (ênfase meu):
Os padrões de design que propomos compartilham um princípio orientador comum: Uma vez que um agente LLM ingeriu entrada não confiável, ele deve ser restringido para que seja impossível Para essa entrada, desencadear quaisquer ações conseqüentesIsto é, ações com efeitos colaterais negativos no sistema ou em seu ambiente. No mínimo, isso significa que os agentes restritos não devem ser capazes de invocar ferramentas que podem quebrar a integridade ou a confidencialidade do sistema. Além disso, suas saídas não devem representar riscos a jusante – como exfiltrar informações confidenciais (por exemplo, por meio de links incorporados) ou manipular o comportamento futuro do agente (por exemplo, respostas nocivas a uma consulta de usuário).
A maneira como penso nisso é que qualquer exposição a tokens potencialmente maliciosos manta inteiramente a saída para esse prompt. Qualquer invasor que possa se esgueirar em seus tokens deve ser considerado um controle total sobre o que acontece a seguir – o que significa que eles controlam não apenas a saída textual do LLM, mas também qualquer ferramenta que o LLM possa invocar.
Vamos falar sobre seus padrões de design.
O padrão de seletor de ação
Um padrão relativamente simples que torna os agentes imunes a solicitar injeções – enquanto ainda permitem que eles tomem ações externas – é impedir qualquer feedback dessas ações de volta ao agente.
Os agentes podem desencadear ferramentas, mas não podem ser expostos ou agir nas respostas de Essas ferramentas. Você não pode ler um email ou recuperar uma página da web, mas pode acionar ações como “Enviar o usuário para esta página da web” ou “Exibir esta mensagem para o usuário”.
Eles resumem esse padrão como uma “declaração de switch modulada por LLM”, que parece precisa para mim.
O padrão de plano-then-Execute
Uma abordagem mais permissiva é permitir o feedback das saídas da ferramenta de volta ao agente, mas para impedir que as saídas da ferramenta influência a escolha das ações tomadas pelo agente.
A idéia aqui é planejar as chamadas da ferramenta com antecedência antes de qualquer chance de exposição a conteúdo não confiável. Isso permite sequências de ações mais sofisticadas, sem o risco de que uma dessas ações possa introduzir instruções maliciosas que desencadeiam ações prejudiciais não planejadas posteriormente.
O exemplo deles converte “Envie a programação de hoje para o meu chefe John Doe” em um calendar.read() chamada de ferramenta seguida por um email.write(..., 'john.doe@company.com'). O calendar.read() A saída pode ser capaz de corromper o corpo do email enviado, mas não será capaz de alterar o destinatário desse email.
O padrão de redes de mapa LLM
O padrão anterior ainda permitia instruções maliciosas para afetar o contente enviado para o próximo passo. O padrão de redução de mapa envolve sub-agentes direcionados pelo coordenador, expostos a conteúdo não confiável e seus resultados agregados com segurança posteriormente.
No exemplo deles, é solicitado que um agente encontre arquivos contendo as faturas deste mês e enviá -las para o departamento de contabilidade. Cada arquivo é processado por um sub-agente que responde com um booleano indicando se o arquivo é relevante ou não. Os arquivos que foram julgados relevantes são então agregados e enviados.
Eles chamam isso de padrão de redes de mapa porque reflete a estrutura clássica do Reduce para Computação Distribuída.
O padrão LLM duplo
Eu recebo uma citação aqui! Descrevi o padrão Dual LLM para construir assistentes de IA que possam resistir à injeção imediata em abril de 2023 e também influenciou o papel de camelo.
Eles descrevem meu padrão exato e até ilustram -o com este diagrama:
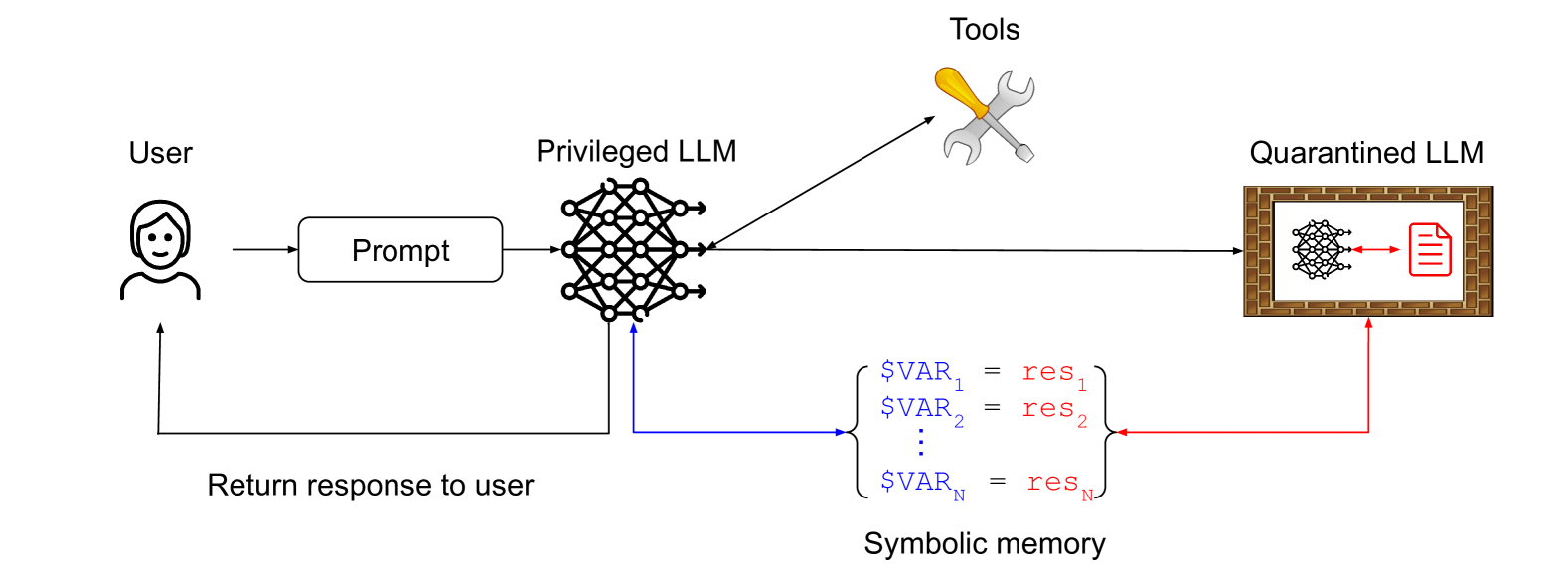
A idéia principal aqui é que um LLM privilegiado coordena um LLM em quarentena, evitando qualquer exposição a conteúdo não confiável. O LLM em quarentena retorna variáveis simbólicas –$VAR1 Representando uma página da Web resumida, por exemplo – que o LLM privilegiado pode solicitar é mostrado ao usuário sem ser exposto a esse conteúdo contaminado.
O padrão de código-then-Execute
Este é o padrão descrito pelo papel de camelo de DeepMind. É uma versão aprimorada do meu padrão LLM duplo, onde o LLM privilegiado gera código em um DSL personalizado que especifica quais ferramentas devem ser chamadas e como suas saídas devem ser transmitidas uma para a outra.
O DSL foi projetado para ativar a análise completa do fluxo de dados, de modo que todos os dados contaminados possam ser marcados como tal e rastreados durante todo o processo.
O padrão de minimização do contexto
Para evitar certas injeções de prompt do usuário, o sistema do agente pode remover conteúdo desnecessário do contexto sobre várias interações.
Por exemplo, suponha que um usuário malicioso peça a um chatbot de atendimento ao cliente uma cotação em um carro novo e tente injetar o agente a dar um grande desconto. O sistema pode garantir que o agente traduz primeiro a solicitação do usuário em uma consulta de banco de dados (por exemplo, para encontrar as ofertas mais recentes). Então, antes de devolver os resultados ao cliente, o prompt do usuário é removido do contexto, impedindo assim a injeção imediata.
Estou um pouco confuso com este, mas acho que entendo o que está dizendo. Se o prompt de um usuário for convertido em uma consulta SQL que retorne dados brutos de um banco de dados e esses dados serão retornados de uma maneira que não possa incluir nenhum dos texto do prompt original, qualquer chance de uma injeção rápida que se esgote deve ser eliminada.
Os estudos de caso
O restante do artigo apresenta dez estudos de caso para ilustrar como esses padrões de design podem ser aplicados na prática, cada um acompanhado por modelos de ameaças detalhados e estratégias de mitigação em potencial.
A maioria deles é extremamente prática e detalhada. O Agente SQL O estudo de caso, por exemplo, envolve um LLM com ferramentas para acessar bancos de dados SQL e escrever e executar o código Python para ajudar na análise desses dados. Este é um altamente Ambiente desafiador para injeção imediata, e o artigo gasta três páginas explorando padrões para construir isso de maneira responsável.
Aqui está a lista completa de estudos de caso. Vale a pena passar tempo com qualquer um que corresponda ao trabalho que você está fazendo:
- OS Assistant
- Agente SQL
- Assistente de e -mail e calendário
- Atendimento ao cliente Chatbot
- Assistente de reserva
- Recomendador de produto
- Retomar assistente de triagem
- Folheto de medicamentos Chatbot
- Diagnóstico médico chatbot
- Agente de engenharia de software
Aqui está uma sugestão interessante daquela última Agente de engenharia de software Estudo de caso sobre como consumir informações de API com segurança de documentação externa não confiável:
O design mais seguro que podemos considerar aqui é aquele em que o agente de código interage apenas com documentação ou código não confiável por meio de uma interface estritamente formatada (por exemplo, em vez de ver código ou documentação arbitrária, o agente vê apenas uma descrição formal da API). Isso pode ser alcançado processando dados não confiáveis com um LLM em quarentena que é instruído a converter os dados em uma descrição da API com requisitos de formatação estritos para minimizar o risco de injeções rápidas (por exemplo, nomes de métodos limitados a 30 caracteres).
- Utilidade: O utilitário é reduzido porque o agente só pode ver APIs e nenhuma descrições de linguagem natural ou exemplos de código de terceiros.
- Segurança: Injeções rápidas teriam que sobreviver sendo formatadas em uma descrição da API, o que é improvável se os requisitos de formatação forem rigorosos o suficiente.
Gostaria de saber se é realmente seguro permitir até 30 nomes de métodos de caracteres … pode ser que um atacante verdadeiramente criativo possa criar um nome de método como run_rm_dash_rf_for_compliance() Isso causa o estrago até mesmo receber essas restrições.
Pensamentos finais
Escrevo sobre injeção imediata há quase três anos, mas nunca tive a paciência de tentar produzir um artigo formal sobre o assunto. É um grande alívio ver os documentos dessa qualidade começando a surgir.
A injeção imediata continua sendo o maior desafio para implantar com responsabilidade o tipo de sistema agêntico que todos estão muito empolgados em construir. Quanto mais atenção essa família de problemas chegar da comunidade de pesquisa, melhor.




")