
Introdução aos bancos de dados de vetores e como usar IA para SEO
Um banco de dados vetorial é uma coleção de dados onde cada dado é armazenado como um vetor (numérico). Um vetor representa um objeto ou entidade, como uma imagem, pessoa, lugar, etc. no espaço N-dimensional abstrato.
Os vetores, conforme explicado no capítulo anterior, são cruciais para identificar como as entidades estão relacionadas e podem ser usados para encontrar sua similaridade semântica. Isso pode ser aplicado de várias maneiras para SEO – como agrupar palavras-chave ou conteúdo semelhantes (usando kNN).
Neste artigo, aprenderemos algumas maneiras de aplicar IA ao SEO, incluindo encontrar conteúdo semanticamente semelhante para links internos. Isso pode ajudá-lo a refinar sua estratégia de conteúdo em uma era em que os mecanismos de pesquisa dependem cada vez mais de LLMs.
Você também pode ler um artigo anterior desta série sobre como encontrar a canibalização de palavras-chave usando embeddings de texto do OpenAI.
Vamos nos aprofundar aqui para começar a construir a base de nossa ferramenta.
Compreendendo bancos de dados vetoriais
Se você tiver milhares de artigos e quiser encontrar a semelhança semântica mais próxima para sua consulta de destino, não poderá criar embeddings vetoriais para todos eles para comparação em tempo real, pois isso é altamente ineficiente.
Para que isso acontecesse, precisaríamos gerar embeddings de vetores apenas uma vez e mantê-los em um banco de dados que possamos consultar e encontrar o artigo com correspondência mais próxima.
E é isso que os bancos de dados vetoriais fazem: são tipos especiais de bancos de dados que armazenam embeddings (vetores).
Quando você consulta o banco de dados, ao contrário dos bancos de dados tradicionais, eles realizam correspondência de similaridade de cosseno e retornam vetores (neste caso, artigos) mais próximos de outro vetor (neste caso, uma frase de palavra-chave) que está sendo consultado.
Aqui está o que parece:
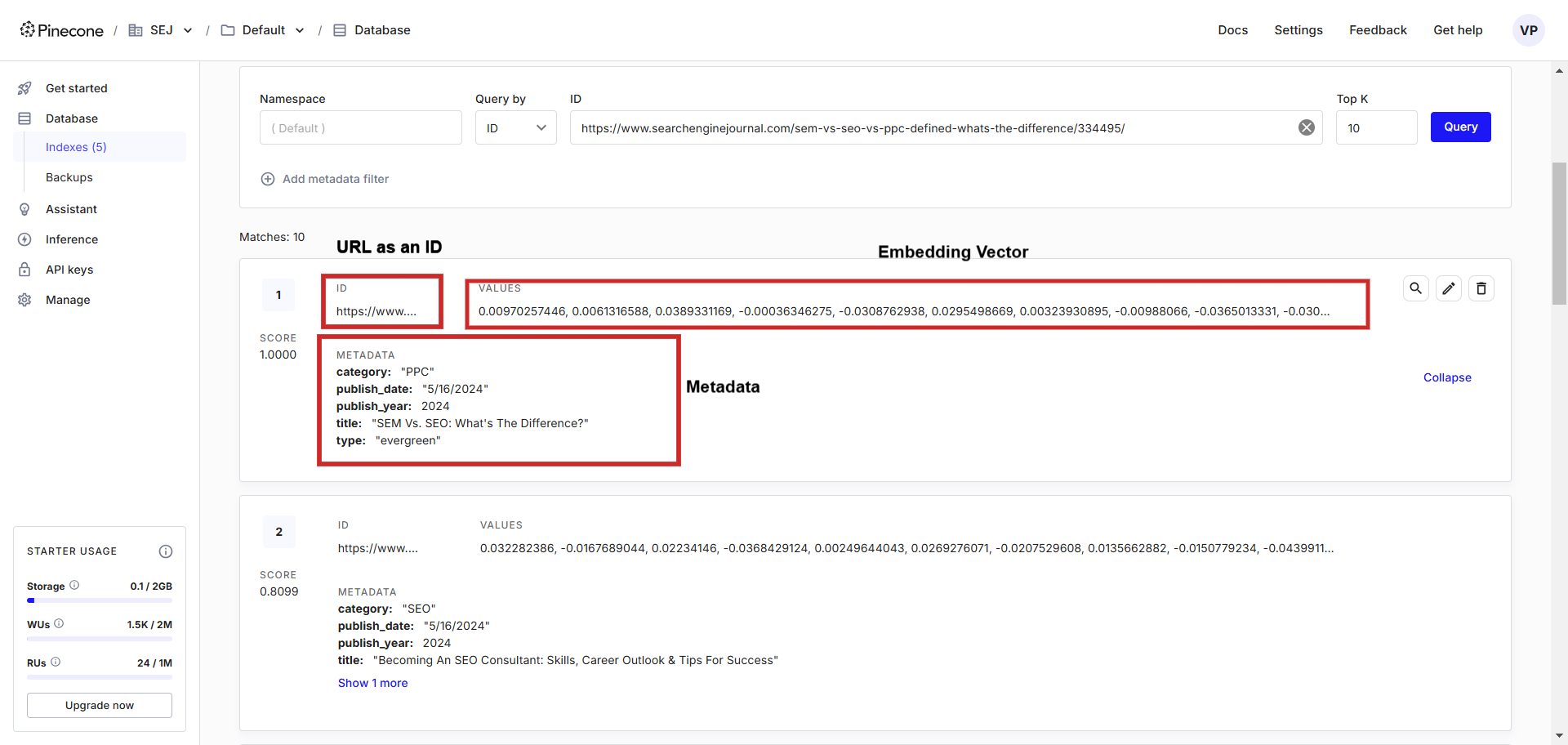 Exemplo de registro de incorporação de texto no banco de dados vetorial.
Exemplo de registro de incorporação de texto no banco de dados vetorial.No banco de dados de vetores, você pode ver os vetores junto com os metadados armazenados, que podemos consultar facilmente usando uma linguagem de programação de nossa escolha.
Neste artigo, usaremos o Pinecone devido à sua facilidade de compreensão e simplicidade de uso, mas existem outros provedores, como Chroma, BigQuery ou Qdrant, que você pode querer conferir.
Vamos mergulhar.
1. Crie um banco de dados vetorial
Primeiro, registre uma conta na Pinecone e crie um índice com a configuração “text-embedding-ada-002” com ‘cosseno’ como métrica para medir a distância do vetor. Você pode nomear o índice como quiser, nós o nomearemosarticle-index-all-ada‘.
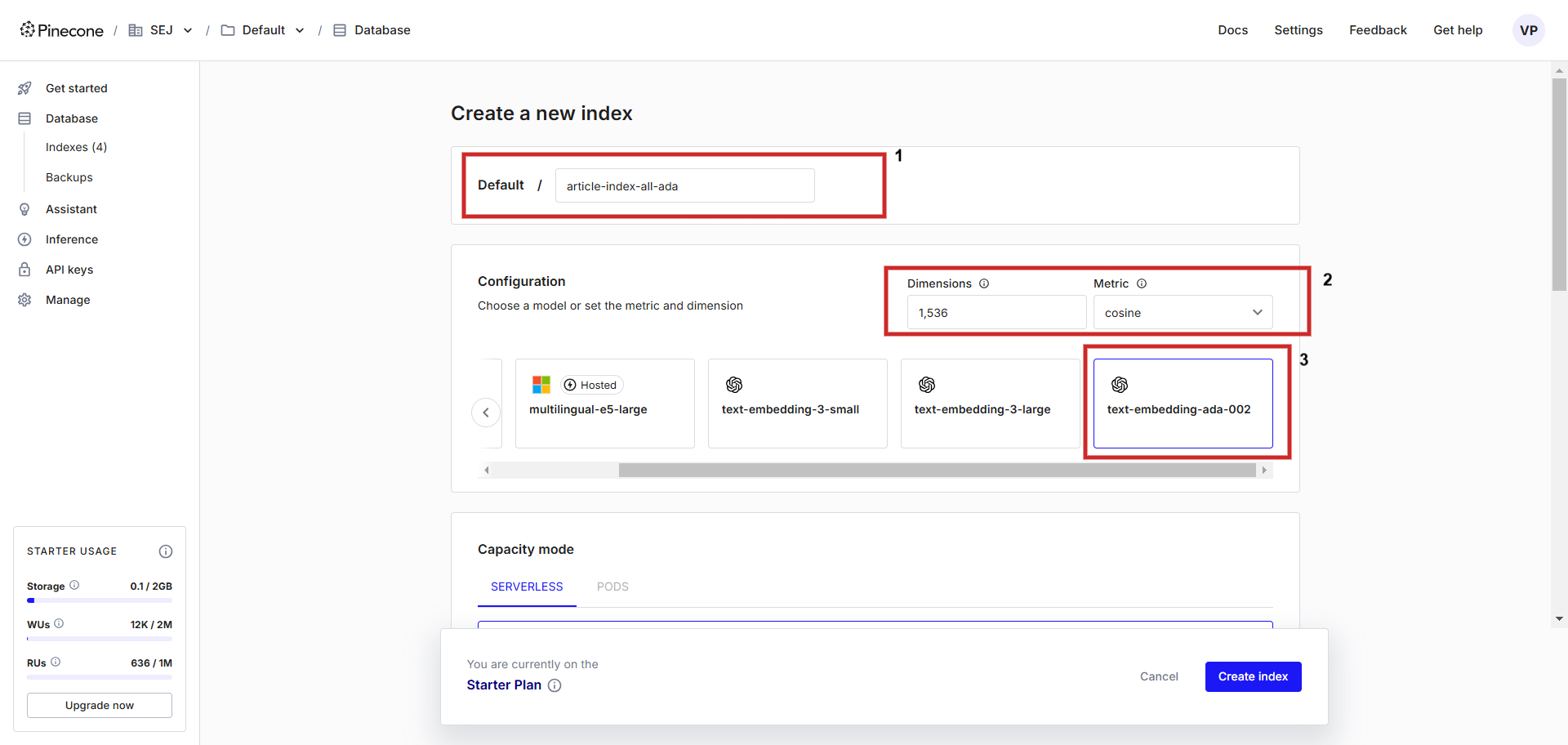 Criando um banco de dados vetorial.
Criando um banco de dados vetorial.Esta UI auxiliar serve apenas para ajudá-lo durante a configuração, caso você queira armazenar a incorporação de vetores do Vertex AI, você precisa definir ‘dimensões’ para 768 na tela de configuração manualmente para corresponder à dimensionalidade padrão e você pode armazenar vetores de texto do Vertex AI (você pode definir o valor da dimensão entre 1 e 768 para economizar memória).
Neste artigo, aprenderemos como usar os modelos ‘text-embedding-ada-002’ da OpenAi e ‘text-embedding-005’ da Vertex AI do Google.
Uma vez criado, precisamos de uma chave API para podermos nos conectar ao banco de dados usando uma URL de host do banco de dados vetorial.
Gere uma chave de API
URL do host do banco de dados vetorial
Em seguida, você precisará usar o Jupyter Notebook. Caso não o tenha instalado, siga este guia para instalá-lo e execute este comando (abaixo) no terminal do seu PC para instalar todos os pacotes necessários.
pip install openai google-cloud-aiplatform google-auth pandas pinecone-client tabulate ipython numpyE lembre-se que o ChatGPT é muito útil quando você encontra problemas durante a codificação!
2. Exporte seus artigos do seu CMS
Em seguida, precisamos preparar um arquivo CSV de exportação de artigos do seu CMS. Se você usa WordPress, pode usar um plugin para fazer exportações personalizadas.
Como nosso objetivo final é construir uma ferramenta de vinculação interna, precisamos decidir quais dados devem ser enviados para o banco de dados vetorial como metadados. Essencialmente, a filtragem baseada em metadados atua como uma camada adicional de orientação de recuperação, alinhando-a com a estrutura geral do RAG ao incorporar conhecimento externo, o que ajudará a melhorar a qualidade da recuperação.
Por exemplo, se estivermos editando um artigo sobre “PPC” e quisermos inserir um link para a frase “Pesquisa de palavras-chave”, podemos especificar em nossa ferramenta que “Categoria=PPC”. Isso permitirá que a ferramenta consulte apenas artigos dentro da categoria “PPC”, garantindo links precisos e contextualmente relevantes, ou podemos querer vincular à frase “atualização mais recente do Google” e limitar a correspondência apenas a artigos de notícias usando ‘Digite ‘ e publicado este ano.
No nosso caso, estaremos exportando:
- Título.
Categoria. - Tipo.
- Data de publicação.
- Ano de publicação.
- Link permanente.
- Meta descrição.
- Contente.
Para ajudar a retornar os melhores resultados, concatenaríamos os campos de título e meta descrições, pois são a melhor representação do artigo que podemos vetorizar e ideais para fins de incorporação e links internos.
Usar o conteúdo completo do artigo para incorporações pode reduzir a precisão e diluir a relevância dos vetores.
Isso acontece porque uma única incorporação grande tenta representar vários tópicos abordados no artigo de uma só vez, levando a uma representação menos focada e relevante. Estratégias de chunking (dividir o artigo por títulos naturais ou segmentos semanticamente significativos) precisam ser aplicadas, mas estas não são o foco deste artigo.
Aqui está o arquivo de exportação de amostra que você pode baixar e usar em nosso exemplo de código abaixo.
2. Inserindo incorporações de texto do OpenAi no banco de dados de vetores
Supondo que você já tenha uma chave de API OpenAI, este código irá gerar embeddings vetoriais a partir do texto e inseri-los no banco de dados de vetores no Pinecone.
import pandas as pd
from openai import OpenAI
from pinecone import Pinecone
from IPython.display import clear_output
# Setup your OpenAI and Pinecone API keys
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI client
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY')
# Connect to an existing Pinecone index
index_name = "article-index-all-ada"
index = pinecone.Index(index_name)
def generate_embeddings(text):
"""
Generates an embedding for the given text using OpenAI's API.
Returns None if text is invalid or an error occurs.
"""
try:
if not text or not isinstance(text, str):
raise ValueError("Input text must be a non-empty string.")
result = openai_client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
clear_output(wait=True) # Clear output for a fresh display
if hasattr(result, 'data') and len(result.data) > 0:
print("API Response:", result)
return result.data(0).embedding
else:
raise ValueError("Invalid response from the OpenAI API. No data returned.")
except ValueError as ve:
print(f"ValueError: {ve}")
return None
except Exception as e:
print(f"An error occurred while generating embeddings: {e}")
return None
# Load your articles from a CSV
df = pd.read_csv('Sample Export File.csv')
# Process each article
for idx, row in df.iterrows():
try:
clear_output(wait=True)
content = row("Content")
vector = generate_embeddings(content)
if vector is None:
print(f"Skipping article ID {row('ID')} due to empty or invalid embedding.")
continue
index.upsert(vectors=(
(
row('Permalink'), # Unique ID
vector, # The embedding
{
'title': row('Title'),
'category': row('Category'),
'type': row('Type'),
'publish_date': row('Publish Date'),
'publish_year': row('Publish Year')
}
)
))
except Exception as e:
clear_output(wait=True)
print(f"Error processing article ID {row('ID')}: {str(e)}")
print("Embeddings are successfully stored in the vector database.")
Você precisa criar um arquivo de notebook, copiá-lo e colá-lo nele e, em seguida, fazer upload do arquivo CSV ‘Sample Export File.csv’ na mesma pasta.
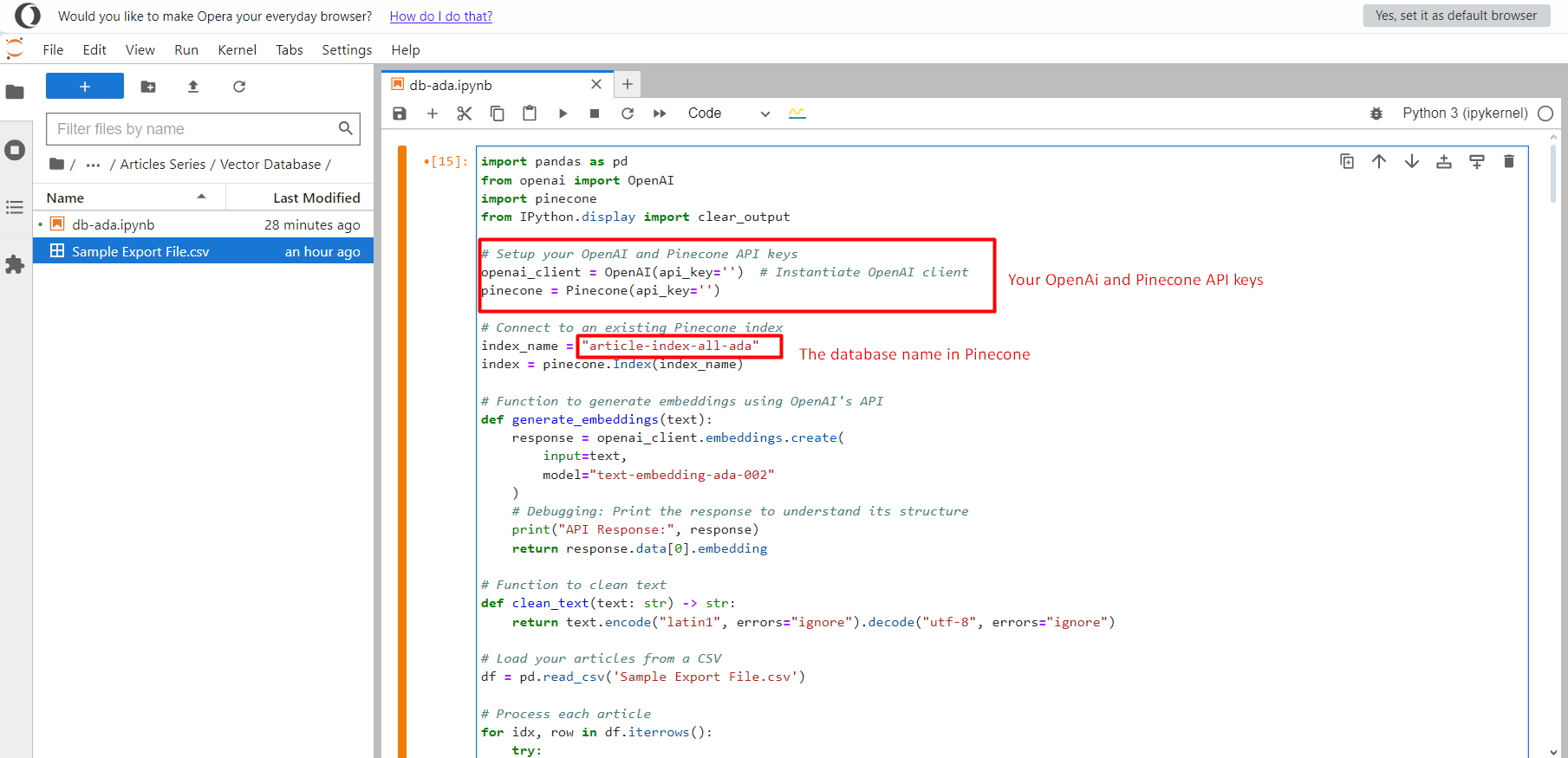 Projeto Júpiter.
Projeto Júpiter.Uma vez feito isso, clique no botão Executar e ele começará a enviar todos os vetores de incorporação de texto para o índice article-index-all-ada criamos na primeira etapa.
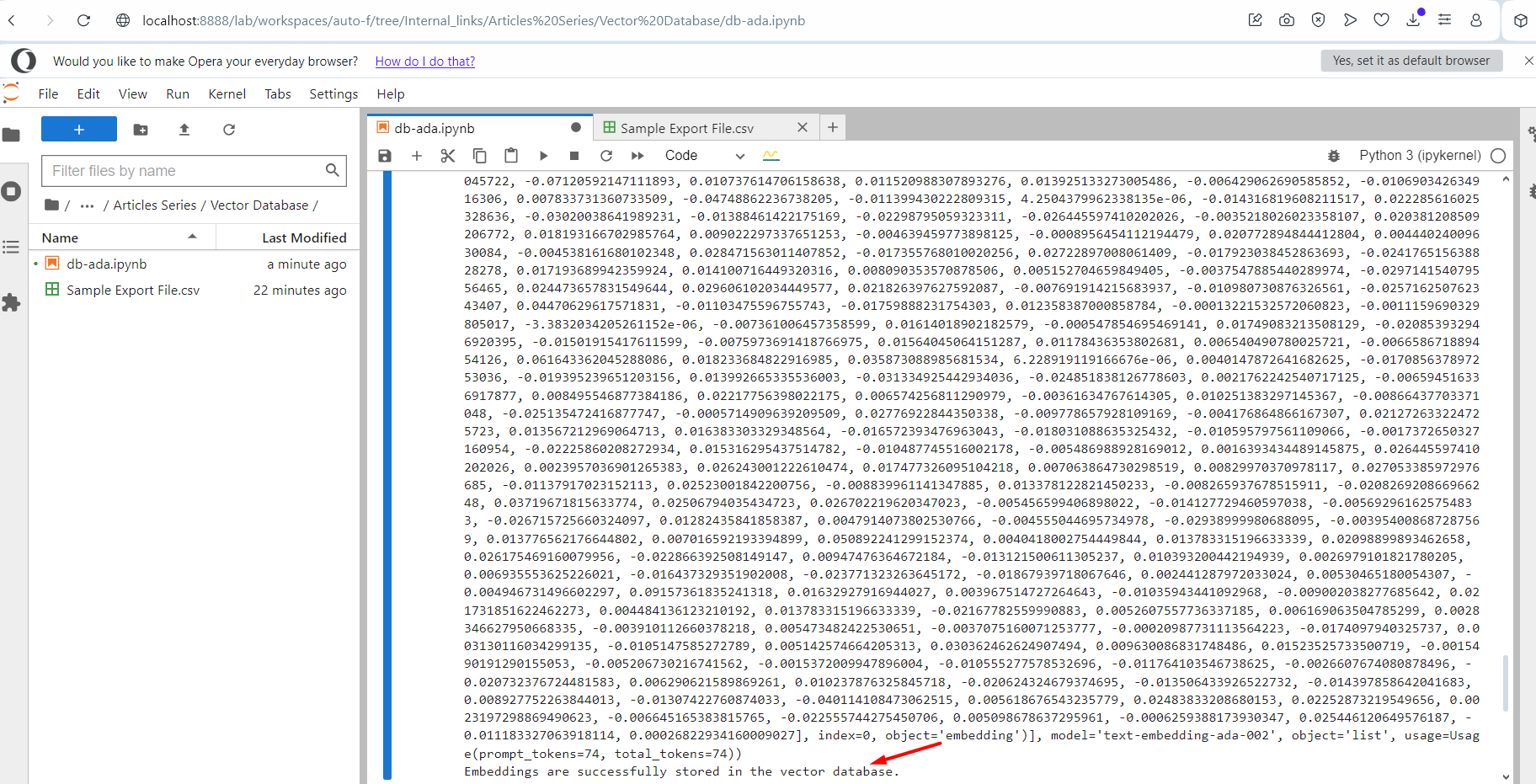 Executando o script.
Executando o script.Você verá um texto de log de saída de vetores incorporados. Ao finalizar, aparecerá a mensagem no final informando que foi finalizado com sucesso. Agora vá e verifique seu índice no Pinecone e você verá que seus registros estão lá.
3. Encontrar uma correspondência de artigo para uma palavra-chave
Ok, agora vamos tentar encontrar uma correspondência de artigo para a palavra-chave.
Crie um novo arquivo de notebook e copie e cole este código.
from openai import OpenAI
from pinecone import Pinecone
from IPython.display import clear_output
from tabulate import tabulate # Import tabulate for table formatting
# Setup your OpenAI and Pinecone API keys
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI client
pinecone = Pinecone(api_key='YOUR_OPENAI_API_KEY')
# Connect to an existing Pinecone index
index_name = "article-index-all-ada"
index = pinecone.Index(index_name)
# Function to generate embeddings using OpenAI's API
def generate_embeddings(text):
"""
Generates an embedding for a given text using OpenAI's API.
"""
try:
if not text or not isinstance(text, str):
raise ValueError("Input text must be a non-empty string.")
result = openai_client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
# Debugging: Print the response to understand its structure
clear_output(wait=True)
#print("API Response:", result)
if hasattr(result, 'data') and len(result.data) > 0:
return result.data(0).embedding
else:
raise ValueError("Invalid response from the OpenAI API. No data returned.")
except ValueError as ve:
print(f"ValueError: {ve}")
return None
except Exception as e:
print(f"An error occurred while generating embeddings: {e}")
return None
# Function to query the Pinecone index with keywords and metadata
def match_keywords_to_index(keywords):
"""
Matches a list of keywords to the closest article in the Pinecone index, filtering by metadata dynamically.
"""
results = ()
for keyword_pair in keywords:
try:
clear_output(wait=True)
# Extract the keyword and category from the sub-array
keyword = keyword_pair(0)
category = keyword_pair(1)
# Generate embedding for the current keyword
vector = generate_embeddings(keyword)
if vector is None:
print(f"Skipping keyword '{keyword}' due to embedding error.")
continue
# Query the Pinecone index for the closest vector with metadata filter
query_results = index.query(
vector=vector, # The embedding of the keyword
top_k=1, # Retrieve only the closest match
include_metadata=True, # Include metadata in the results
filter={"category": category} # Filter results by metadata category dynamically
)
# Store the closest match
if query_results('matches'):
closest_match = query_results('matches')(0)
results.append({
'Keyword': keyword, # The searched keyword
'Category': category, # The category used for filtering
'Match Score': f"{closest_match('score'):.2f}", # Similarity score (formatted to 2 decimal places)
'Title': closest_match('metadata').get('title', 'N/A'), # Title of the article
'URL': closest_match('id') # Using 'id' as the URL
})
else:
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'N/A',
'Title': 'No match found',
'URL': 'N/A'
})
except Exception as e:
clear_output(wait=True)
print(f"Error processing keyword '{keyword}' with category '{category}': {e}")
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'Error',
'Title': 'Error occurred',
'URL': 'N/A'
})
return results
# Example usage: Find matches for an array of keywords and categories
keywords = (("SEO Tools", "SEO"), ("TikTok", "TikTok"), ("SEO Consultant", "SEO")) # Replace with your keywords and categories
matches = match_keywords_to_index(keywords)
# Display the results in a table
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
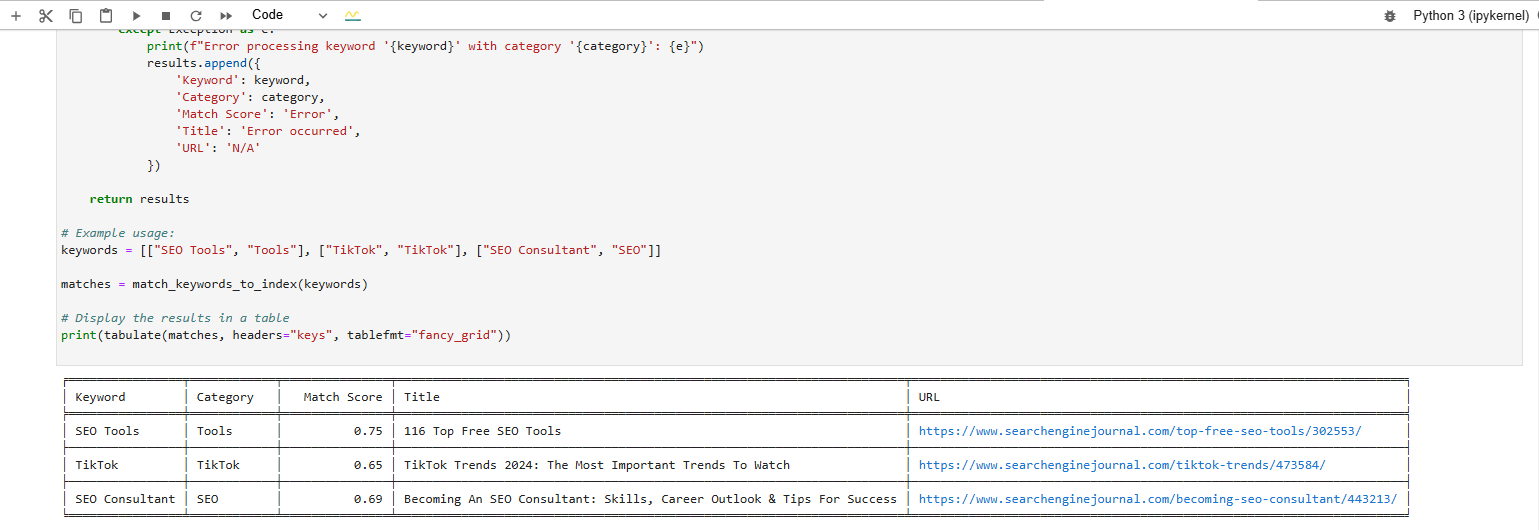
Estamos tentando encontrar uma correspondência para estas palavras-chave:
- Ferramentas de SEO.
- TikTok.
- Consultor SEO.
E este é o resultado que obtemos após executar o código:
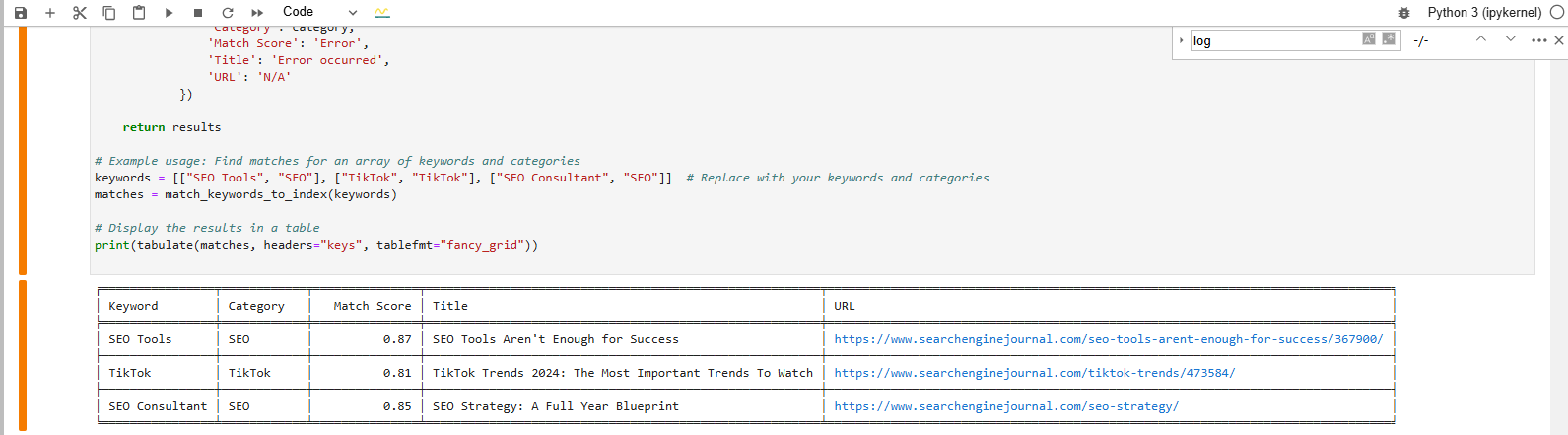 Encontre uma correspondência para a frase de palavra-chave no banco de dados vetorial
Encontre uma correspondência para a frase de palavra-chave no banco de dados vetorialA saída formatada em tabela na parte inferior mostra as correspondências de artigos mais próximas de nossas palavras-chave.
4. Inserindo incorporações de texto do Google Vertex AI no banco de dados de vetores
Agora vamos fazer o mesmo, mas com Google Vertex AI ‘text-embedding-005‘incorporação. Este modelo é notável porque foi desenvolvido pelo Google, alimenta o Vertex AI Search e é treinado especificamente para lidar com tarefas de recuperação e correspondência de consultas, tornando-o adequado para nosso caso de uso.
Você pode até criar um widget de pesquisa interno e adicioná-lo ao seu site.
Comece fazendo login no Console do Google Cloud e crie um projeto. Em seguida, na biblioteca de APIs, encontre a API Vertex AI e ative-a.
 Captura de tela do Console do Google Cloud, dezembro de 2024
Captura de tela do Console do Google Cloud, dezembro de 2024Configure sua conta de faturamento para poder usar o Vertex AI, pois o preço é de US$ 0,0002 por 1.000 caracteres (e oferece créditos de US$ 300 para novos usuários).
Depois de configurá-lo, você precisa navegar até Serviços API> Credenciais, criar uma conta de serviço, gerar uma chave e baixá-la como JSON.
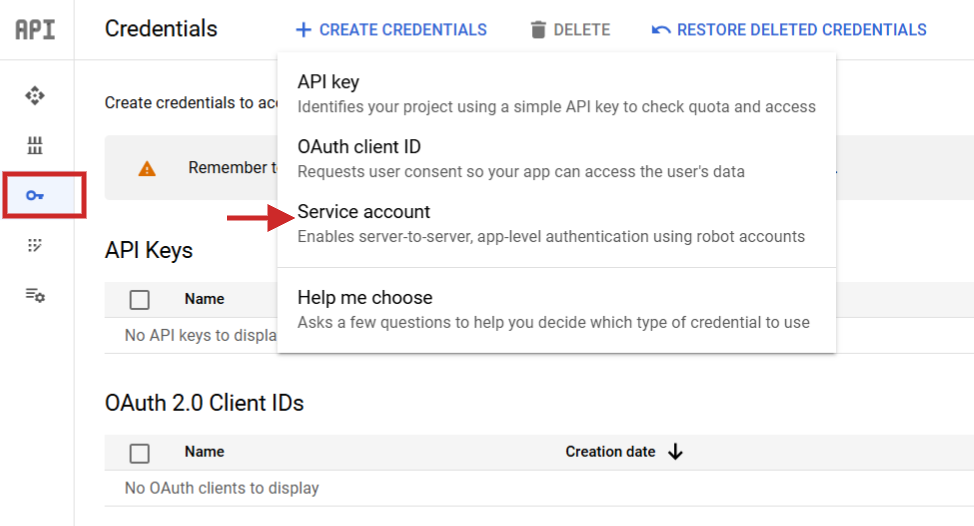
Etapa 1: crie uma conta de serviço
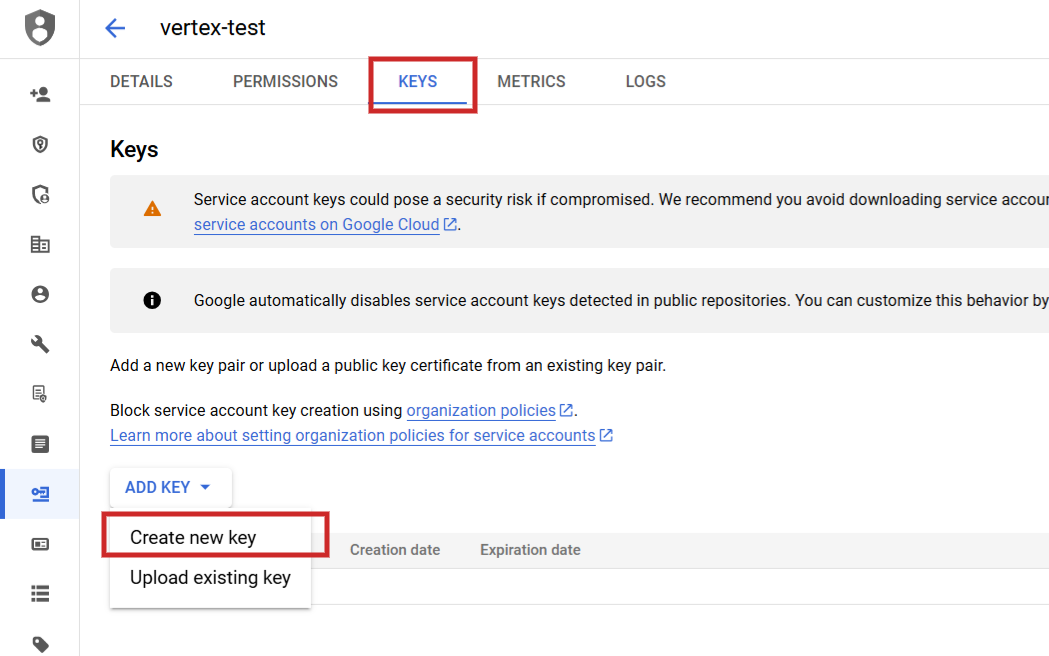
Etapa 2: adicionar nova chave na guia Chaves da conta de serviço

Etapa 3: crie uma chave JSON
Renomeie o arquivo JSON para config.json e carregue-o (por meio do ícone de seta para cima) para a pasta do projeto do Jupyter Notebook.
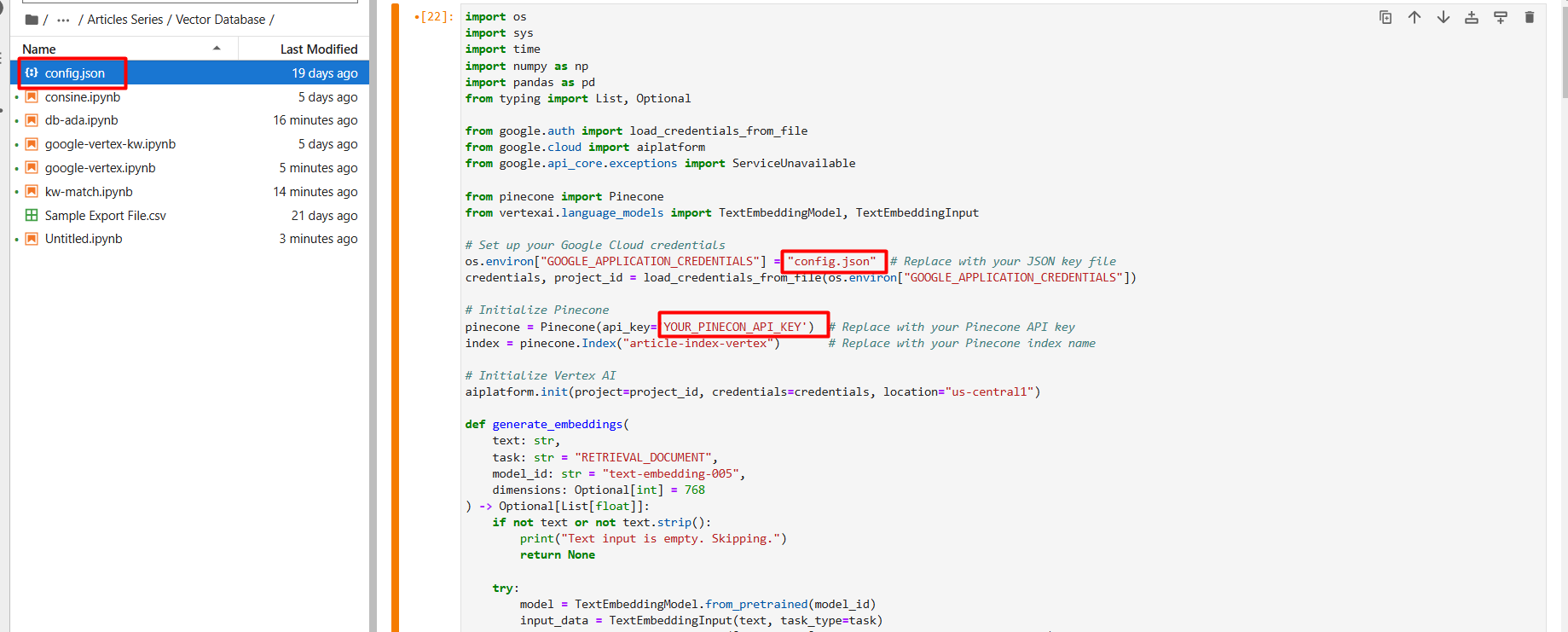 Captura de tela do Console do Google Cloud, dezembro de 2024
Captura de tela do Console do Google Cloud, dezembro de 2024Na primeira etapa de configuração, crie um novo banco de dados vetorial chamado article-index-vertex definindo a dimensão 768 manualmente.
Depois de criado, você pode executar este script para começar a gerar embeddings vetoriais a partir do mesmo arquivo de amostra usando o Google Vertex AI text-embedding-005 modelo (você pode escolher text-multilingual-embedding-002 se tiver texto que não seja em inglês).
import os
import sys
import time
import numpy as np
import pandas as pd
from typing import List, Optional
from google.auth import load_credentials_from_file
from google.cloud import aiplatform
from google.api_core.exceptions import ServiceUnavailable
from pinecone import Pinecone
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
# Set up your Google Cloud credentials
os.environ("GOOGLE_APPLICATION_CREDENTIALS") = "config.json" # Replace with your JSON key file
credentials, project_id = load_credentials_from_file(os.environ("GOOGLE_APPLICATION_CREDENTIALS"))
# Initialize Pinecone
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Replace with your Pinecone API key
index = pinecone.Index("article-index-vertex") # Replace with your Pinecone index name
# Initialize Vertex AI
aiplatform.init(project=project_id, credentials=credentials, location="us-central1")
def generate_embeddings(
text: str,
task: str = "RETRIEVAL_DOCUMENT",
model_id: str = "text-embedding-005",
dimensions: Optional(int) = 768
) -> Optional(List(float)):
if not text or not text.strip():
print("Text input is empty. Skipping.")
return None
try:
model = TextEmbeddingModel.from_pretrained(model_id)
input_data = TextEmbeddingInput(text, task_type=task)
vectors = model.get_embeddings((input_data), output_dimensionality=dimensions)
return vectors(0).values
except ServiceUnavailable as e:
print(f"Vertex AI service is unavailable: {e}")
return None
except Exception as e:
print(f"Error generating embeddings: {e}")
return None
# Load data from CSV
data = pd.read_csv("Sample Export File.csv") # Replace with your CSV file path
for idx, row in data.iterrows():
try:
permalink = str(row("Permalink"))
content = row("Content")
embedding = generate_embeddings(content)
if not embedding:
print(f"Skipping article ID {row('ID')} due to empty or failed embedding.")
continue
print(f"Embedding for {permalink}: {embedding(:5)}...")
sys.stdout.flush()
index.upsert(vectors=(
(
permalink,
embedding,
{
'category': row('Category'),
'title': row('Title'),
'publish_date': row('Publish Date'),
'type': row('Type'),
'publish_year': row('Publish Year')
}
)
))
time.sleep(1) # Optional: Sleep to avoid rate limits
except Exception as e:
print(f"Error processing article ID {row('ID')}: {e}")
print("All embeddings are stored in the vector database.")
Você verá abaixo nos logs dos embeddings criados.
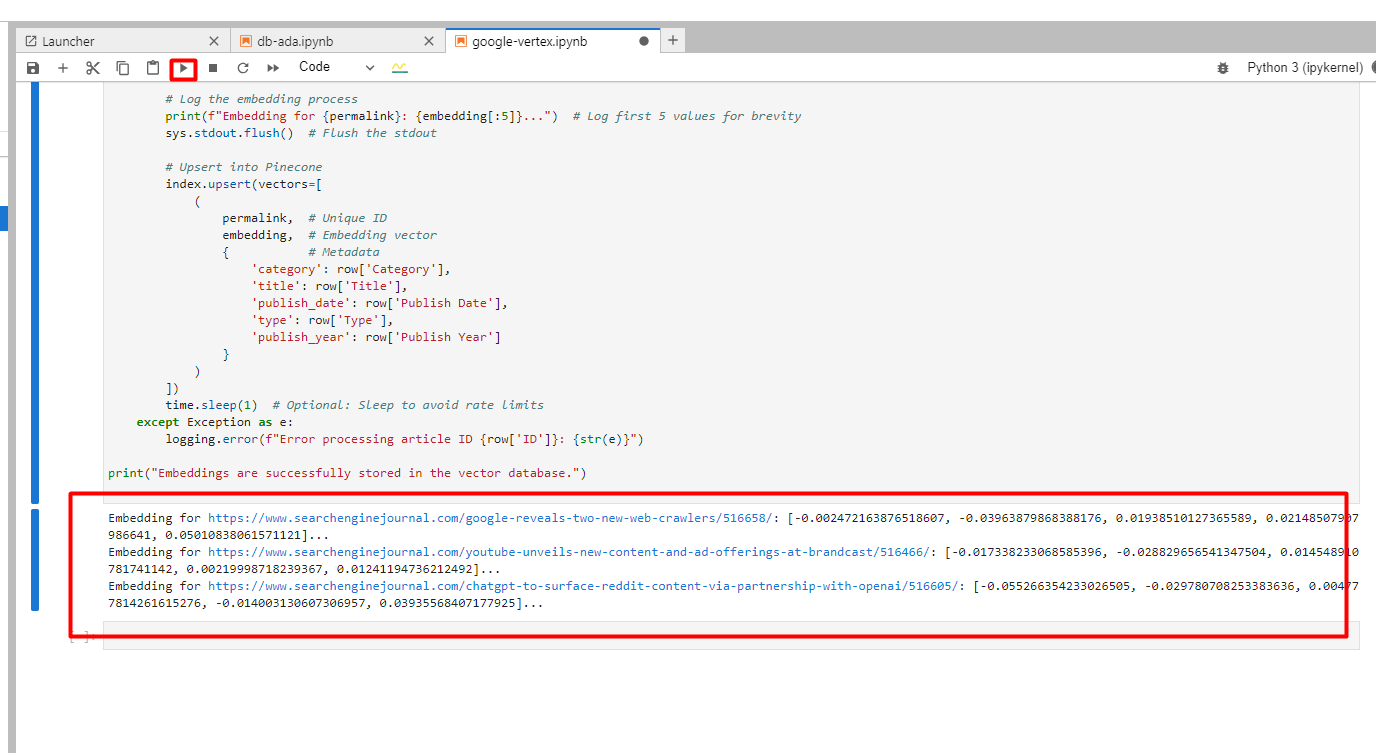 Captura de tela do Console do Google Cloud, dezembro de 2024
Captura de tela do Console do Google Cloud, dezembro de 20244. Encontrar uma correspondência de artigo para uma palavra-chave usando o Google Vertex AI
Agora, vamos fazer a mesma correspondência de palavras-chave com a Vertex AI. Há uma pequena nuance, pois você precisa usar ‘RETRIEVAL_QUERY’ vs. ‘RETRIEVAL_DOCUMENT’ como argumento ao gerar incorporações de palavras-chave, pois estamos tentando realizar uma pesquisa por um artigo (também conhecido como documento) que melhor corresponda à nossa frase.
Os tipos de tarefas são uma das vantagens importantes que o Vertex AI tem sobre os modelos do OpenAI.
Ele garante que os embeddings capturem a intenção das palavras-chave, o que é importante para links internos, e melhora a relevância e a precisão das correspondências encontradas em seu banco de dados de vetores.
Use este script para combinar as palavras-chave com os vetores.
import os
import pandas as pd
from google.cloud import aiplatform
from google.auth import load_credentials_from_file
from google.api_core.exceptions import ServiceUnavailable
from vertexai.language_models import TextEmbeddingModel
from pinecone import Pinecone
from tabulate import tabulate # For table formatting
# Set up your Google Cloud credentials
os.environ("GOOGLE_APPLICATION_CREDENTIALS") = "config.json" # Replace with your JSON key file
credentials, project_id = load_credentials_from_file(os.environ("GOOGLE_APPLICATION_CREDENTIALS"))
# Initialize Pinecone client
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Add your Pinecone API key
index_name = "article-index-vertex" # Replace with your Pinecone index name
index = pinecone.Index(index_name)
# Initialize Vertex AI
aiplatform.init(project=project_id, credentials=credentials, location="us-central1")
def generate_embeddings(
text: str,
model_id: str = "text-embedding-005"
) -> list:
"""
Generates embeddings for the input text using Google Vertex AI's embedding model.
Returns None if text is empty or an error occurs.
"""
if not text or not text.strip():
print("Text input is empty. Skipping.")
return None
try:
model = TextEmbeddingModel.from_pretrained(model_id)
vector = model.get_embeddings((text)) # Removed 'task_type' and 'output_dimensionality'
return vector(0).values
except ServiceUnavailable as e:
print(f"Vertex AI service is unavailable: {e}")
return None
except Exception as e:
print(f"Error generating embeddings: {e}")
return None
def match_keywords_to_index(keywords):
"""
Matches a list of keyword-category pairs to the closest articles in the Pinecone index,
filtering by metadata if specified.
"""
results = ()
for keyword_pair in keywords:
keyword = keyword_pair(0)
category = keyword_pair(1)
try:
keyword_vector = generate_embeddings(keyword)
if not keyword_vector:
print(f"No embedding generated for keyword '{keyword}' in category '{category}'.")
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'Error/Empty',
'Title': 'No match',
'URL': 'N/A'
})
continue
query_results = index.query(
vector=keyword_vector,
top_k=1,
include_metadata=True,
filter={"category": category}
)
if query_results('matches'):
closest_match = query_results('matches')(0)
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': f"{closest_match('score'):.2f}",
'Title': closest_match('metadata').get('title', 'N/A'),
'URL': closest_match('id')
})
else:
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'N/A',
'Title': 'No match found',
'URL': 'N/A'
})
except Exception as e:
print(f"Error processing keyword '{keyword}' with category '{category}': {e}")
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'Error',
'Title': 'Error occurred',
'URL': 'N/A'
})
return results
# Example usage:
keywords = (("SEO Tools", "Tools"), ("TikTok", "TikTok"), ("SEO Consultant", "SEO"))
matches = match_keywords_to_index(keywords)
# Display the results in a table
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
E você verá pontuações geradas:
 Pontuações de correspondência de palavras-chave produzidas pelo modelo de incorporação de texto Vertex AI
Pontuações de correspondência de palavras-chave produzidas pelo modelo de incorporação de texto Vertex AITente testar a relevância da redação do seu artigo
Pense nisso como uma maneira simplificada (ampla) de verificar o quão semanticamente semelhante sua escrita é à palavra-chave principal. Crie uma incorporação vetorial de sua palavra-chave principal e de todo o conteúdo do artigo por meio do Vertex AI do Google e calcule uma semelhança de cosseno.
Se o seu texto for muito longo, talvez seja necessário considerar a implementação de estratégias de agrupamento.
Uma pontuação próxima (semelhança de cosseno) de 1,0 (como 0,8 ou 0,7) significa que você está bem próximo nesse assunto. Se sua pontuação for mais baixa, você poderá descobrir que uma introdução excessivamente longa e com muitos detalhes pode estar causando diluição da relevância e cortá-la ajuda a aumentá-la.
Mas lembre-se de que quaisquer edições feitas também devem fazer sentido do ponto de vista editorial e da experiência do usuário.
Você pode até fazer uma comparação rápida incorporando o conteúdo de alto nível de um concorrente e vendo como você se sai.
Fazer isso ajuda você a alinhar seu conteúdo com mais precisão com o assunto alvo, o que pode ajudá-lo a se classificar melhor.
Já existem ferramentas que realizam essas tarefas, mas aprender essas habilidades significa que você pode adotar uma abordagem personalizada e adaptada às suas necessidades – e, é claro, fazê-lo gratuitamente.
Experimentar você mesmo e aprender essas habilidades o ajudará a se manter à frente com AI SEO e a tomar decisões informadas.
Como leituras adicionais, recomendo que você mergulhe nestes ótimos artigos:
Mais recursos:
Imagem em destaque: Aozorastock/Shutterstock




