
Como usar o LLMS para 301 redirecionamentos em escala
Os redirecionamentos são essenciais para a manutenção de todos os sites, e o gerenciamento de redirecionamentos se torna realmente desafiador quando os profissionais de SEO lidam com sites contendo milhões de páginas.
Exemplos de situações em que você pode precisar implementar redirecionamentos em escala:
- Um site de comércio eletrônico possui um grande número de produtos que não são mais vendidos.
- As páginas desatualizadas das publicações de notícias não são mais relevantes ou carecem de valor histórico.
- Listagem de diretórios que contêm listagens desatualizadas.
- Os quadros de empregos onde as postagens expira.
Por que o redirecionamento em escala é essencial?
Pode ajudar a melhorar a experiência do usuário, consolidar rankings e economizar orçamento de rastreamento.
Você pode considerar o NoIndexing, mas isso não impede o Googlebot de rastejar. Ele desperdiça o orçamento de rastreamento à medida que o número de páginas cresce.
Do ponto de vista da experiência do usuário, o pouso em um link desatualizado é frustrante. Por exemplo, se um usuário chegar a uma listagem de empregos desatualizada, é melhor enviá -lo para a correspondência mais próxima para uma listagem de empregos ativa.
No The Search Engine Journal, obtemos muitos links 404 do AI Chatbots por causa de alucinações ao inventar URLs que nunca existiram.
Usamos os relatórios do Google Analytics 4 e o Google Search Console (e às vezes os registros de servidores) relatam para extrair essas 404 páginas e redirecioná -las para o conteúdo correspondente mais próximo com base no artigo.
Quando os chatbots nos citam através de 404 páginas, e as pessoas continuam passando por links quebrados, não é uma boa experiência do usuário.
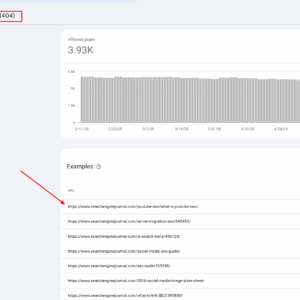
404 URLs Relatório no GSC, maio de 2025
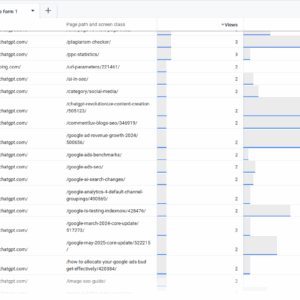
404 visitas de AI Chatbots, maio de 2025
Prepare candidatos a redirecionamento
Primeiro de tudo, leia esta postagem para aprender como criar um banco de dados de vetor pinecone. (Observe que, neste caso, usamos “Primary_Category” como uma chave de metadados vs. “categoria”.
Para fazer isso funcionar, assumimos que todos os seus vetores de artigo já estão armazenados no banco de dados “Artigo-Index-Vertex”.
Prepare seus URLs de redirecionamento no formato CSV, como neste arquivo de amostra. Podem ser artigos existentes que você decidiu podar ou 404s de seus relatórios de console de pesquisa ou GA4.
 Exemplo de arquivo com URLs a serem redirecionados (captura de tela do Google Sheet, maio de 2025)
Exemplo de arquivo com URLs a serem redirecionados (captura de tela do Google Sheet, maio de 2025)As informações opcionais “Primary_Category” são metadados que existem com os registros Pinecone de seus artigos quando você os criou e pode ser usado para filtrar artigos da mesma categoria, aumentando ainda mais a precisão.
Caso falta o título, por exemplo, em 404 URLs, o script extrairá palavras de lesma do URL e as usará como entrada.
Gerar redirecionamentos usando o google vértice ai
Faça o download das suas credenciais de serviço da API do Google e renomeie -as como “config.json”, envie o script abaixo e um arquivo de amostra para o mesmo diretório no Jupyter Lab e execute -o.
import os
import time
import logging
from urllib.parse import urlparse
import re
import pandas as pd
from pandas.errors import EmptyDataError
from typing import Optional, List, Dict, Any
from google.auth import load_credentials_from_file
from google.cloud import aiplatform
from google.api_core.exceptions import GoogleAPIError
from pinecone import Pinecone, PineconeException
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
# Import tenacity for retry mechanism. Tenacity provides a decorator to add retry logic
# to functions, making them more robust against transient errors like network issues or API rate limits.
from tenacity import retry, wait_exponential, stop_after_attempt, retry_if_exception_type
# For clearing output in Jupyter (optional, keep if running in Jupyter).
# This is useful for interactive environments to show progress without cluttering the output.
from IPython.display import clear_output
# ─── USER CONFIGURATION ───────────────────────────────────────────────────────
# Define configurable parameters for the script. These can be easily adjusted
# without modifying the core logic.
INPUT_CSV = "redirect_candidates.csv" # Path to the input CSV file containing URLs to be redirected.
# Expected columns: "URL", "Title", "primary_category".
OUTPUT_CSV = "redirect_map.csv" # Path to the output CSV file where the generated redirect map will be saved.
PINECONE_API_KEY = "YOUR_PINECONE_KEY" # Your API key for Pinecone. Replace with your actual key.
PINECONE_INDEX_NAME = "article-index-vertex" # The name of the Pinecone index where article vectors are stored.
GOOGLE_CRED_PATH = "config.json" # Path to your Google Cloud service account credentials JSON file.
EMBEDDING_MODEL_ID = "text-embedding-005" # Identifier for the Vertex AI text embedding model to use.
TASK_TYPE = "RETRIEVAL_QUERY" # The task type for the embedding model. Try with RETRIEVAL_DOCUMENT vs RETRIEVAL_QUERY to see the difference.
# This influences how the embedding vector is generated for optimal retrieval.
CANDIDATE_FETCH_COUNT = 3 # Number of potential redirect candidates to fetch from Pinecone for each input URL.
TEST_MODE = True # If True, the script will process only a small subset of the input data (MAX_TEST_ROWS).
# Useful for testing and debugging.
MAX_TEST_ROWS = 5 # Maximum number of rows to process when TEST_MODE is True.
QUERY_DELAY = 0.2 # Delay in seconds between successive API queries (to avoid hitting rate limits).
PUBLISH_YEAR_FILTER: List(int) = () # Optional: List of years to filter Pinecone results by 'publish_year' metadata.
# If empty, no year filtering is applied.
LOG_BATCH_SIZE = 5 # Number of URLs to process before flushing the results to the output CSV.
# This helps in saving progress incrementally and managing memory.
MIN_SLUG_LENGTH = 3 # Minimum length for a URL slug segment to be considered meaningful for embedding.
# Shorter segments might be noise or less descriptive.
# Retry configuration for API calls (Vertex AI and Pinecone).
# These parameters control how the `tenacity` library retries failed API requests.
MAX_RETRIES = 5 # Maximum number of times to retry an API call before giving up.
INITIAL_RETRY_DELAY = 1 # Initial delay in seconds before the first retry.
# Subsequent retries will have exponentially increasing delays.
# ─── SETUP LOGGING ─────────────────────────────────────────────────────────────
# Configure the logging system to output informational messages to the console.
logging.basicConfig(
level=logging.INFO, # Set the logging level to INFO, meaning INFO, WARNING, ERROR, CRITICAL messages will be shown.
format="%(asctime)s %(levelname)s %(message)s" # Define the format of log messages (timestamp, level, message).
)
# ─── INITIALIZE GOOGLE VERTEX AI ───────────────────────────────────────────────
# Set the GOOGLE_APPLICATION_CREDENTIALS environment variable to point to the
# service account key file. This allows the Google Cloud client libraries to
# authenticate automatically.
os.environ("GOOGLE_APPLICATION_CREDENTIALS") = GOOGLE_CRED_PATH
try:
# Load credentials from the specified JSON file.
credentials, project_id = load_credentials_from_file(GOOGLE_CRED_PATH)
# Initialize the Vertex AI client with the project ID and credentials.
# The location "us-central1" is specified for the AI Platform services.
aiplatform.init(project=project_id, credentials=credentials, location="us-central1")
logging.info("Vertex AI initialized.")
except Exception as e:
# Log an error if Vertex AI initialization fails and re-raise the exception
# to stop script execution, as it's a critical dependency.
logging.error(f"Failed to initialize Vertex AI: {e}")
raise
# Initialize the embedding model once globally.
# This is a crucial optimization for "Resource Management for Embedding Model".
# Loading the model takes time and resources; doing it once avoids repeated loading
# for every URL processed, significantly improving performance.
try:
GLOBAL_EMBEDDING_MODEL = TextEmbeddingModel.from_pretrained(EMBEDDING_MODEL_ID)
logging.info(f"Text Embedding Model '{EMBEDDING_MODEL_ID}' loaded.")
except Exception as e:
# Log an error if the embedding model fails to load and re-raise.
# The script cannot proceed without the embedding model.
logging.error(f"Failed to load Text Embedding Model: {e}")
raise
# ─── INITIALIZE PINECONE ──────────────────────────────────────────────────────
# Initialize the Pinecone client and connect to the specified index.
try:
pinecone = Pinecone(api_key=PINECONE_API_KEY)
index = pinecone.Index(PINECONE_INDEX_NAME)
logging.info(f"Connected to Pinecone index '{PINECONE_INDEX_NAME}'.")
except PineconeException as e:
# Log an error if Pinecone initialization fails and re-raise.
# Pinecone is a critical dependency for finding redirect candidates.
logging.error(f"Pinecone init error: {e}")
raise
# ─── HELPERS ───────────────────────────────────────────────────────────────────
def canonical_url(url: str) -> str:
"""
Converts a given URL into its canonical form by:
1. Stripping query strings (e.g., `?param=value`) and URL fragments (e.g., `#section`).
2. Handling URL-encoded fragment markers (`%23`).
3. Preserving the trailing slash if it was present in the original URL's path.
This ensures consistency with the original site's URL structure.
Args:
url (str): The input URL.
Returns:
str: The canonicalized URL.
"""
# Remove query parameters and URL fragments.
temp = url.split('?', 1)(0).split('#', 1)(0)
# Check for URL-encoded fragment markers and remove them.
enc_idx = temp.lower().find('%23')
if enc_idx != -1:
temp = temp(:enc_idx)
# Determine if the original URL path ended with a trailing slash.
has_slash = urlparse(temp).path.endswith('/')
# Remove any trailing slash temporarily for consistent processing.
temp = temp.rstrip('/')
# Re-add the trailing slash if it was originally present.
return temp + ('/' if has_slash else '')
def slug_from_url(url: str) -> str:
"""
Extracts and joins meaningful, non-numeric path segments from a canonical URL
to form a "slug" string. This slug can be used as text for embedding when
a URL's title is not available.
Args:
url (str): The input URL.
Returns:
str: A hyphen-separated string of relevant slug parts.
"""
clean = canonical_url(url) # Get the canonical version of the URL.
path = urlparse(clean).path # Extract the path component of the URL.
segments = (seg for seg in path.split('/') if seg) # Split path into segments and remove empty ones.
# Filter segments based on criteria:
# - Not purely numeric (e.g., '123' is excluded).
# - Length is greater than or equal to MIN_SLUG_LENGTH.
# - Contains at least one alphanumeric character (to exclude purely special character segments).
parts = (seg for seg in segments
if not seg.isdigit()
and len(seg) >= MIN_SLUG_LENGTH
and re.search(r'(A-Za-z0-9)', seg))
return '-'.join(parts) # Join the filtered parts with hyphens.
# ─── EMBEDDING GENERATION FUNCTION ─────────────────────────────────────────────
# Apply retry mechanism for GoogleAPIError. This makes the embedding generation
# more resilient to transient issues like network problems or Vertex AI rate limits.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10), # Exponential backoff for retries.
stop=stop_after_attempt(MAX_RETRIES), # Stop retrying after a maximum number of attempts.
retry=retry_if_exception_type(GoogleAPIError), # Only retry if a GoogleAPIError occurs.
reraise=True # Re-raise the exception if all retries fail, allowing the calling function to handle it.
)
def generate_embedding(text: str) -> Optional(List(float)):
"""
Generates a vector embedding for the given text using the globally initialized
Vertex AI Text Embedding Model. Includes retry logic for API calls.
Args:
text (str): The input text (e.g., URL title or slug) to embed.
Returns:
Optional(List(float)): A list of floats representing the embedding vector,
or None if the input text is empty/whitespace or
if an unexpected error occurs after retries.
"""
if not text or not text.strip():
# If the text is empty or only whitespace, no embedding can be generated.
return None
try:
# Use the globally initialized model to get embeddings.
# This is the "Resource Management for Embedding Model" optimization.
inp = TextEmbeddingInput(text, task_type=TASK_TYPE)
vectors = GLOBAL_EMBEDDING_MODEL.get_embeddings((inp), output_dimensionality=768)
return vectors(0).values # Return the embedding vector (list of floats).
except GoogleAPIError as e:
# Log a warning if a GoogleAPIError occurs, then re-raise to trigger the `tenacity` retry mechanism.
logging.warning(f"Vertex AI error during embedding generation (retrying): {e}")
raise # The `reraise=True` in the decorator will catch this and retry.
except Exception as e:
# Catch any other unexpected exceptions during embedding generation.
logging.error(f"Unexpected error generating embedding: {e}")
return None # Return None for non-retryable or final failed attempts.
# ─── MAIN PROCESSING FUNCTION ─────────────────────────────────────────────────
def build_redirect_map(
input_csv: str,
output_csv: str,
fetch_count: int,
test_mode: bool
):
"""
Builds a redirect map by processing URLs from an input CSV, generating
embeddings, querying Pinecone for similar articles, and identifying
suitable redirect candidates.
Args:
input_csv (str): Path to the input CSV file.
output_csv (str): Path to the output CSV file for the redirect map.
fetch_count (int): Number of candidates to fetch from Pinecone.
test_mode (bool): If True, process only a limited number of rows.
"""
# Read the input CSV file into a Pandas DataFrame.
df = pd.read_csv(input_csv)
required = {"URL", "Title", "primary_category"}
# Validate that all required columns are present in the DataFrame.
if not required.issubset(df.columns):
raise ValueError(f"Input CSV must have columns: {required}")
# Create a set of canonicalized input URLs for efficient lookup.
# This is used to prevent an input URL from redirecting to itself or another input URL,
# which could create redirect loops or redirect to a page that is also being redirected.
input_urls = set(df("URL").map(canonical_url))
start_idx = 0
# Implement resume functionality: if the output CSV already exists,
# try to find the last processed URL and resume from the next row.
if os.path.exists(output_csv):
try:
prev = pd.read_csv(output_csv)
except EmptyDataError:
# Handle case where the output CSV exists but is empty.
prev = pd.DataFrame()
if not prev.empty:
# Get the last URL that was processed and written to the output file.
last = prev("URL").iloc(-1)
# Find the index of this last URL in the original input DataFrame.
idxs = df.index(df("URL").map(canonical_url) == last).tolist()
if idxs:
# Set the starting index for processing to the row after the last processed URL.
start_idx = idxs(0) + 1
logging.info(f"Resuming from row {start_idx} after {last}.")
# Determine the range of rows to process based on test_mode.
if test_mode:
end_idx = min(start_idx + MAX_TEST_ROWS, len(df))
df_proc = df.iloc(start_idx:end_idx) # Select a slice of the DataFrame for testing.
logging.info(f"Test mode: processing rows {start_idx} to {end_idx-1}.")
else:
df_proc = df.iloc(start_idx:) # Process all remaining rows.
logging.info(f"Processing rows {start_idx} to {len(df)-1}.")
total = len(df_proc) # Total number of URLs to process in this run.
processed = 0 # Counter for successfully processed URLs.
batch: List(Dict(str, Any)) = () # List to store results before flushing to CSV.
# Iterate over each row (URL) in the DataFrame slice to be processed.
for _, row in df_proc.iterrows():
raw_url = row("URL") # Original URL from the input CSV.
url = canonical_url(raw_url) # Canonicalized version of the URL.
# Get title and category, handling potential missing values by defaulting to empty strings.
title = row("Title") if isinstance(row("Title"), str) else ""
category = row("primary_category") if isinstance(row("primary_category"), str) else ""
# Determine the text to use for generating the embedding.
# Prioritize the 'Title' if available, otherwise use a slug derived from the URL.
if title.strip():
text = title
else:
slug = slug_from_url(raw_url)
if not slug:
# If no meaningful slug can be extracted, skip this URL.
logging.info(f"Skipping {raw_url}: insufficient slug context for embedding.")
continue
text = slug.replace('-', ' ') # Prepare slug for embedding by replacing hyphens with spaces.
# Attempt to generate the embedding for the chosen text.
# This call is wrapped in a try-except block to catch final failures after retries.
try:
embedding = generate_embedding(text)
except GoogleAPIError as e:
# If embedding generation fails even after retries, log the error and skip this URL.
logging.error(f"Failed to generate embedding for {raw_url} after {MAX_RETRIES} retries: {e}")
continue # Move to the next URL.
if not embedding:
# If `generate_embedding` returned None (e.g., empty text or unexpected error), skip.
logging.info(f"Skipping {raw_url}: no embedding generated.")
continue
# Build metadata filter for Pinecone query.
# This helps narrow down search results to more relevant candidates (e.g., by category or publish year).
filt: Dict(str, Any) = {}
if category:
# Split category string by comma and strip whitespace for multiple categories.
cats = (c.strip() for c in category.split(",") if c.strip())
if cats:
filt("primary_category") = {"$in": cats} # Filter by categories present in Pinecone metadata.
if PUBLISH_YEAR_FILTER:
filt("publish_year") = {"$in": PUBLISH_YEAR_FILTER} # Filter by specified publish years.
filt("id") = {"$ne": url} # Exclude the current URL itself from the search results to prevent self-redirects.
# Define a nested function for Pinecone query with retry mechanism.
# This ensures that Pinecone queries are also robust against transient errors.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10),
stop=stop_after_attempt(MAX_RETRIES),
retry=retry_if_exception_type(PineconeException), # Only retry if a PineconeException occurs.
reraise=True # Re-raise the exception if all retries fail.
)
def query_pinecone_with_retry(embedding_vector, top_k_count, pinecone_filter):
"""
Performs a Pinecone index query with retry logic.
"""
return index.query(
vector=embedding_vector,
top_k=top_k_count,
include_values=False, # We don't need the actual vector values in the response.
include_metadata=False, # We don't need the metadata in the response for this logic.
filter=pinecone_filter # Apply the constructed metadata filter.
)
# Attempt to query Pinecone for redirect candidates.
try:
res = query_pinecone_with_retry(embedding, fetch_count, filt)
except PineconeException as e:
# If Pinecone query fails after retries, log the error and skip this URL.
logging.error(f"Failed to query Pinecone for {raw_url} after {MAX_RETRIES} retries: {e}")
continue # Move to the next URL.
candidate = None # Initialize redirect candidate to None.
score = None # Initialize relevance score to None.
# Iterate through the Pinecone query results (matches) to find a suitable candidate.
for m in res.get("matches", ()):
cid = m.get("id") # Get the ID (URL) of the matched document in Pinecone.
# A candidate is suitable if:
# 1. It exists (cid is not None).
# 2. It's not the original URL itself (to prevent self-redirects).
# 3. It's not another URL from the input_urls set (to prevent redirecting to a page that's also being redirected).
if cid and cid != url and cid not in input_urls:
candidate = cid # Assign the first valid candidate found.
score = m.get("score") # Get the relevance score of this candidate.
break # Stop after finding the first suitable candidate (Pinecone returns by relevance).
# Append the results for the current URL to the batch.
batch.append({"URL": url, "Redirect Candidate": candidate, "Relevance Score": score})
processed += 1 # Increment the counter for processed URLs.
msg = f"Mapped {url} → {candidate}"
if score is not None:
msg += f" ({score:.4f})" # Add score to log message if available.
logging.info(msg) # Log the mapping result.
# Periodically flush the batch results to the output CSV.
if processed % LOG_BATCH_SIZE == 0:
out_df = pd.DataFrame(batch) # Convert the current batch to a DataFrame.
# Determine file mode: 'a' (append) if file exists, 'w' (write) if new.
mode="a" if os.path.exists(output_csv) else 'w'
# Determine if header should be written (only for new files).
header = not os.path.exists(output_csv)
# Write the batch to the CSV.
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
batch.clear() # Clear the batch after writing to free memory.
if not test_mode:
# clear_output(wait=True) # Uncomment if running in Jupyter and want to clear output
clear_output(wait=True)
print(f"Progress: {processed} / {total}") # Print progress update.
time.sleep(QUERY_DELAY) # Pause for a short delay to avoid overwhelming APIs.
# After the loop, write any remaining items in the batch to the output CSV.
if batch:
out_df = pd.DataFrame(batch)
mode="a" if os.path.exists(output_csv) else 'w'
header = not os.path.exists(output_csv)
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
logging.info(f"Completed. Total processed: {processed}") # Log completion message.
if __name__ == "__main__":
# This block ensures that build_redirect_map is called only when the script is executed directly.
# It passes the user-defined configuration parameters to the main function.
build_redirect_map(INPUT_CSV, OUTPUT_CSV, CANDIDATE_FETCH_COUNT, TEST_MODE)
Você verá um teste executado com apenas cinco registros e verá um novo arquivo chamado “redirect_map.csv”, que contém sugestões de redirecionamento.
Depois de garantir que o código funcione sem problemas, você pode definir o TEST_MODE booleano para verdadeiro False e execute o script para todos os seus URLs.
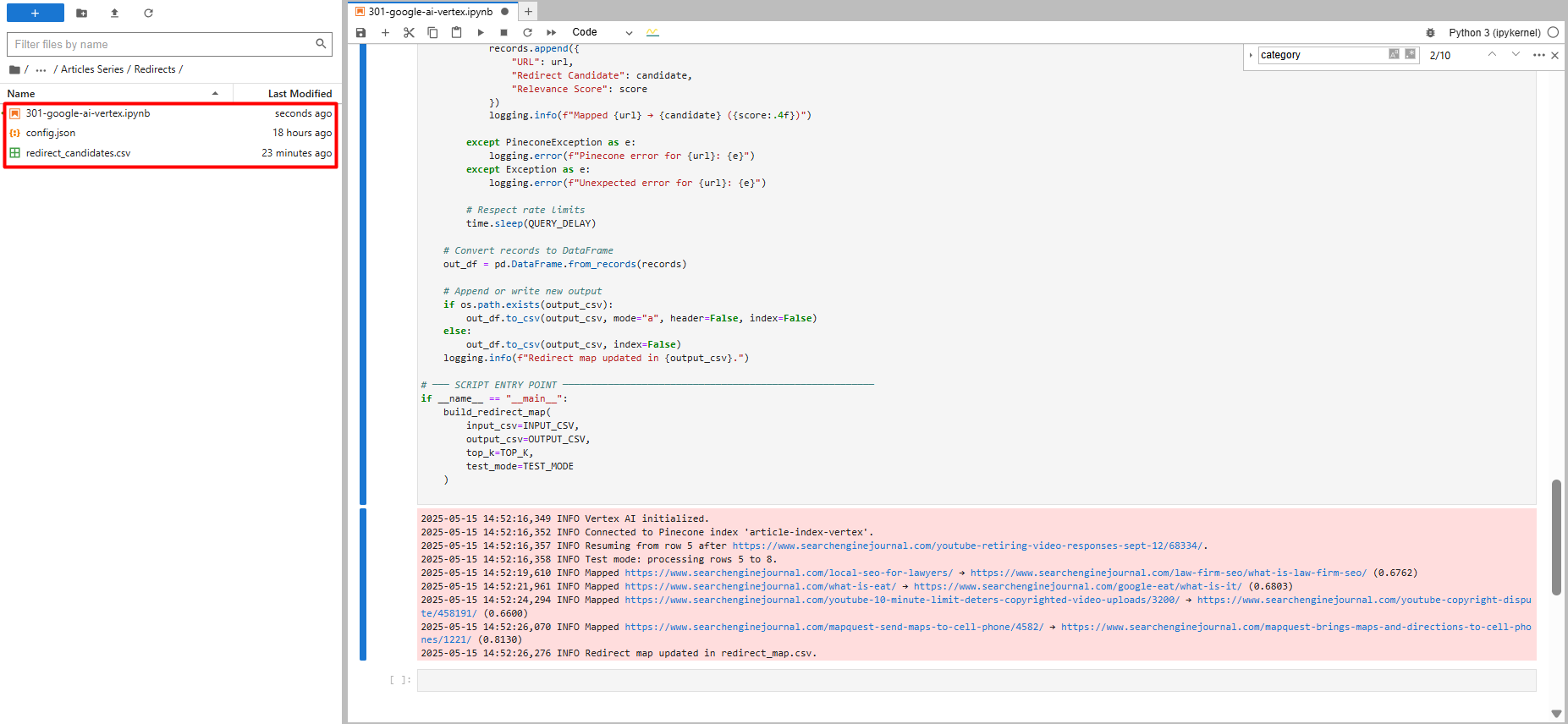 Teste executado com apenas cinco registros (imagem do autor, maio de 2025)
Teste executado com apenas cinco registros (imagem do autor, maio de 2025)Se o código parar e você retomar, ele pega de onde parou. Ele também verifica cada redirecionamento que encontra no arquivo CSV.
Esta verificação impede a seleção de um URL do banco de dados na lista podada. Selecionar esse URL pode causar um loop de redirecionamento infinito.
Para nossos URLs de amostra, a saída é mostrada abaixo.
 Redirecionar os candidatos usando a recuperação do tipo de tarefa do Google Vertex AI (imagem do autor, maio de 2025)
Redirecionar os candidatos usando a recuperação do tipo de tarefa do Google Vertex AI (imagem do autor, maio de 2025)Agora podemos pegar esse mapa de redirecionamento e importá -lo para o nosso gerente de redirecionamento no Sistema de Gerenciamento de Conteúdo (CMS), e é isso!
Você pode ver como ele conseguiu corresponder ao artigo de notícias desatualizado de 2013 “Respostas em vídeo aposentadas do YouTube em 12 de setembro” ao artigo mais recente e altamente relevante de 2022 News “YouTube adota o recurso do Tiktok – Responder aos comentários com um vídeo”.
Também para “/What-Is-Eat/”, encontrou uma correspondência com “/Google-Eat/What-It-It/”, que é uma correspondência 100% perfeita.
Isso não se deve apenas ao poder da qualidade do Google Vertex LLM, mas também ao resultado da escolha dos parâmetros corretos.
Quando uso “recuperação_document” como o tipo de tarefa ao gerar incorporações de vetor de consulta para o artigo de notícias do YouTube mostrado acima, ele corresponde “ao YouTube expande as postagens da comunidade para mais criadores”, que ainda é relevante, mas não uma correspondência tão boa quanto a outra.
Para “/What-Is-Eat/”, ele corresponde ao artigo “/Reimaginando-Eating-to-Drive-Higher-Sales-e-Search-visibilidade/545790/”, que não é tão bom quanto “/Google-Eat/What-IS-It/”.
Se você quiser encontrar correspondências de redirecionamento do seu novo pool de artigos, poderá consultar o Pinecone com um filtro de metadados adicionais, “Publish_year”, se você tiver esse campo de metadados em seus registros Pinecone, que eu recomendo criar.
No código, é um PUBLISH_YEAR_FILTER variável.
Se você tem publish_year Metadados, você pode definir os anos como valores de matriz e puxará artigos publicados nos anos especificados.
Gerar redirecionamentos usando o texto do OpenAI
Vamos realizar a mesma tarefa com o modelo “Text-Ada-002” do OpenAI. O objetivo é mostrar a diferença na saída do Google Vertex AI.
Basta criar um novo arquivo de notebook no mesmo diretório, copiar e colar este código e executá -lo.
import os
import time
import logging
from urllib.parse import urlparse
import re
import pandas as pd
from pandas.errors import EmptyDataError
from typing import Optional, List, Dict, Any
from openai import OpenAI
from pinecone import Pinecone, PineconeException
# Import tenacity for retry mechanism. Tenacity provides a decorator to add retry logic
# to functions, making them more robust against transient errors like network issues or API rate limits.
from tenacity import retry, wait_exponential, stop_after_attempt, retry_if_exception_type
# For clearing output in Jupyter (optional, keep if running in Jupyter)
from IPython.display import clear_output
# ─── USER CONFIGURATION ───────────────────────────────────────────────────────
# Define configurable parameters for the script. These can be easily adjusted
# without modifying the core logic.
INPUT_CSV = "redirect_candidates.csv" # Path to the input CSV file containing URLs to be redirected.
# Expected columns: "URL", "Title", "primary_category".
OUTPUT_CSV = "redirect_map.csv" # Path to the output CSV file where the generated redirect map will be saved.
PINECONE_API_KEY = "YOUR_PINECONE_API_KEY" # Your API key for Pinecone. Replace with your actual key.
PINECONE_INDEX_NAME = "article-index-ada" # The name of the Pinecone index where article vectors are stored.
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY" # Your API key for OpenAI. Replace with your actual key.
OPENAI_EMBEDDING_MODEL_ID = "text-embedding-ada-002" # Identifier for the OpenAI text embedding model to use.
CANDIDATE_FETCH_COUNT = 3 # Number of potential redirect candidates to fetch from Pinecone for each input URL.
TEST_MODE = True # If True, the script will process only a small subset of the input data (MAX_TEST_ROWS).
# Useful for testing and debugging.
MAX_TEST_ROWS = 5 # Maximum number of rows to process when TEST_MODE is True.
QUERY_DELAY = 0.2 # Delay in seconds between successive API queries (to avoid hitting rate limits).
PUBLISH_YEAR_FILTER: List(int) = () # Optional: List of years to filter Pinecone results by 'publish_year' metadata eg. (2024,2025).
# If empty, no year filtering is applied.
LOG_BATCH_SIZE = 5 # Number of URLs to process before flushing the results to the output CSV.
# This helps in saving progress incrementally and managing memory.
MIN_SLUG_LENGTH = 3 # Minimum length for a URL slug segment to be considered meaningful for embedding.
# Shorter segments might be noise or less descriptive.
# Retry configuration for API calls (OpenAI and Pinecone).
# These parameters control how the `tenacity` library retries failed API requests.
MAX_RETRIES = 5 # Maximum number of times to retry an API call before giving up.
INITIAL_RETRY_DELAY = 1 # Initial delay in seconds before the first retry.
# Subsequent retries will have exponentially increasing delays.
# ─── SETUP LOGGING ─────────────────────────────────────────────────────────────
# Configure the logging system to output informational messages to the console.
logging.basicConfig(
level=logging.INFO, # Set the logging level to INFO, meaning INFO, WARNING, ERROR, CRITICAL messages will be shown.
format="%(asctime)s %(levelname)s %(message)s" # Define the format of log messages (timestamp, level, message).
)
# ─── INITIALIZE OPENAI CLIENT & PINECONE ───────────────────────────────────────
# Initialize the OpenAI client once globally. This handles resource management efficiently
# as the client object manages connections and authentication.
client = OpenAI(api_key=OPENAI_API_KEY)
try:
# Initialize the Pinecone client and connect to the specified index.
pinecone = Pinecone(api_key=PINECONE_API_KEY)
index = pinecone.Index(PINECONE_INDEX_NAME)
logging.info(f"Connected to Pinecone index '{PINECONE_INDEX_NAME}'.")
except PineconeException as e:
# Log an error if Pinecone initialization fails and re-raise.
# Pinecone is a critical dependency for finding redirect candidates.
logging.error(f"Pinecone init error: {e}")
raise
# ─── HELPERS ───────────────────────────────────────────────────────────────────
def canonical_url(url: str) -> str:
"""
Converts a given URL into its canonical form by:
1. Stripping query strings (e.g., `?param=value`) and URL fragments (e.g., `#section`).
2. Handling URL-encoded fragment markers (`%23`).
3. Preserving the trailing slash if it was present in the original URL's path.
This ensures consistency with the original site's URL structure.
Args:
url (str): The input URL.
Returns:
str: The canonicalized URL.
"""
# Remove query parameters and URL fragments.
temp = url.split('?', 1)(0)
temp = temp.split('#', 1)(0)
# Check for URL-encoded fragment markers and remove them.
enc_idx = temp.lower().find('%23')
if enc_idx != -1:
temp = temp(:enc_idx)
# Determine if the original URL path ended with a trailing slash.
preserve_slash = temp.endswith('/')
# Strip trailing slash if not originally present.
if not preserve_slash:
temp = temp.rstrip('/')
return temp
def slug_from_url(url: str) -> str:
"""
Extracts and joins meaningful, non-numeric path segments from a canonical URL
to form a "slug" string. This slug can be used as text for embedding when
a URL's title is not available.
Args:
url (str): The input URL.
Returns:
str: A hyphen-separated string of relevant slug parts.
"""
clean = canonical_url(url) # Get the canonical version of the URL.
path = urlparse(clean).path # Extract the path component of the URL.
segments = (seg for seg in path.split('/') if seg) # Split path into segments and remove empty ones.
# Filter segments based on criteria:
# - Not purely numeric (e.g., '123' is excluded).
# - Length is greater than or equal to MIN_SLUG_LENGTH.
# - Contains at least one alphanumeric character (to exclude purely special character segments).
parts = (seg for seg in segments
if not seg.isdigit()
and len(seg) >= MIN_SLUG_LENGTH
and re.search(r'(A-Za-z0-9)', seg))
return '-'.join(parts) # Join the filtered parts with hyphens.
# ─── EMBEDDING GENERATION FUNCTION ─────────────────────────────────────────────
# Apply retry mechanism for OpenAI API errors. This makes the embedding generation
# more resilient to transient issues like network problems or API rate limits.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10), # Exponential backoff for retries.
stop=stop_after_attempt(MAX_RETRIES), # Stop retrying after a maximum number of attempts.
retry=retry_if_exception_type(Exception), # Retry on any Exception from OpenAI client (can be refined to openai.APIError if desired).
reraise=True # Re-raise the exception if all retries fail, allowing the calling function to handle it.
)
def generate_embedding(text: str) -> Optional(List(float)):
"""
Generate a vector embedding for the given text using OpenAI's text-embedding-ada-002
via the globally initialized OpenAI client. Includes retry logic for API calls.
Args:
text (str): The input text (e.g., URL title or slug) to embed.
Returns:
Optional(List(float)): A list of floats representing the embedding vector,
or None if the input text is empty/whitespace or
if an unexpected error occurs after retries.
"""
if not text or not text.strip():
# If the text is empty or only whitespace, no embedding can be generated.
return None
try:
resp = client.embeddings.create( # Use the globally initialized OpenAI client to get embeddings.
model=OPENAI_EMBEDDING_MODEL_ID,
input=text
)
return resp.data(0).embedding # Return the embedding vector (list of floats).
except Exception as e:
# Log a warning if an OpenAI error occurs, then re-raise to trigger the `tenacity` retry mechanism.
logging.warning(f"OpenAI embedding error (retrying): {e}")
raise # The `reraise=True` in the decorator will catch this and retry.
# ─── MAIN PROCESSING FUNCTION ─────────────────────────────────────────────────
def build_redirect_map(
input_csv: str,
output_csv: str,
fetch_count: int,
test_mode: bool
):
"""
Builds a redirect map by processing URLs from an input CSV, generating
embeddings, querying Pinecone for similar articles, and identifying
suitable redirect candidates.
Args:
input_csv (str): Path to the input CSV file.
output_csv (str): Path to the output CSV file for the redirect map.
fetch_count (int): Number of candidates to fetch from Pinecone.
test_mode (bool): If True, process only a limited number of rows.
"""
# Read the input CSV file into a Pandas DataFrame.
df = pd.read_csv(input_csv)
required = {"URL", "Title", "primary_category"}
# Validate that all required columns are present in the DataFrame.
if not required.issubset(df.columns):
raise ValueError(f"Input CSV must have columns: {required}")
# Create a set of canonicalized input URLs for efficient lookup.
# This is used to prevent an input URL from redirecting to itself or another input URL,
# which could create redirect loops or redirect to a page that is also being redirected.
input_urls = set(df("URL").map(canonical_url))
start_idx = 0
# Implement resume functionality: if the output CSV already exists,
# try to find the last processed URL and resume from the next row.
if os.path.exists(output_csv):
try:
prev = pd.read_csv(output_csv)
except EmptyDataError:
# Handle case where the output CSV exists but is empty.
prev = pd.DataFrame()
if not prev.empty:
# Get the last URL that was processed and written to the output file.
last = prev("URL").iloc(-1)
# Find the index of this last URL in the original input DataFrame.
idxs = df.index(df("URL").map(canonical_url) == last).tolist()
if idxs:
# Set the starting index for processing to the row after the last processed URL.
start_idx = idxs(0) + 1
logging.info(f"Resuming from row {start_idx} after {last}.")
# Determine the range of rows to process based on test_mode.
if test_mode:
end_idx = min(start_idx + MAX_TEST_ROWS, len(df))
df_proc = df.iloc(start_idx:end_idx) # Select a slice of the DataFrame for testing.
logging.info(f"Test mode: processing rows {start_idx} to {end_idx-1}.")
else:
df_proc = df.iloc(start_idx:) # Process all remaining rows.
logging.info(f"Processing rows {start_idx} to {len(df)-1}.")
total = len(df_proc) # Total number of URLs to process in this run.
processed = 0 # Counter for successfully processed URLs.
batch: List(Dict(str, Any)) = () # List to store results before flushing to CSV.
# Iterate over each row (URL) in the DataFrame slice to be processed.
for _, row in df_proc.iterrows():
raw_url = row("URL") # Original URL from the input CSV.
url = canonical_url(raw_url) # Canonicalized version of the URL.
# Get title and category, handling potential missing values by defaulting to empty strings.
title = row("Title") if isinstance(row("Title"), str) else ""
category = row("primary_category") if isinstance(row("primary_category"), str) else ""
# Determine the text to use for generating the embedding.
# Prioritize the 'Title' if available, otherwise use a slug derived from the URL.
if title.strip():
text = title
else:
raw_slug = slug_from_url(raw_url)
if not raw_slug or len(raw_slug) < MIN_SLUG_LENGTH:
# If no meaningful slug can be extracted, skip this URL.
logging.info(f"Skipping {raw_url}: insufficient slug context.")
continue
text = raw_slug.replace('-', ' ').replace('_', ' ') # Prepare slug for embedding by replacing hyphens with spaces.
# Attempt to generate the embedding for the chosen text.
# This call is wrapped in a try-except block to catch final failures after retries.
try:
embedding = generate_embedding(text)
except Exception as e: # Catch any exception from generate_embedding after all retries.
# If embedding generation fails even after retries, log the error and skip this URL.
logging.error(f"Failed to generate embedding for {raw_url} after {MAX_RETRIES} retries: {e}")
continue # Move to the next URL.
if not embedding:
# If `generate_embedding` returned None (e.g., empty text or unexpected error), skip.
logging.info(f"Skipping {raw_url}: no embedding.")
continue
# Build metadata filter for Pinecone query.
# This helps narrow down search results to more relevant candidates (e.g., by category or publish year).
filt: Dict(str, Any) = {}
if category:
# Split category string by comma and strip whitespace for multiple categories.
cats = (c.strip() for c in category.split(",") if c.strip())
if cats:
filt("primary_category") = {"$in": cats} # Filter by categories present in Pinecone metadata.
if PUBLISH_YEAR_FILTER:
filt("publish_year") = {"$in": PUBLISH_YEAR_FILTER} # Filter by specified publish years.
filt("id") = {"$ne": url} # Exclude the current URL itself from the search results to prevent self-redirects.
# Define a nested function for Pinecone query with retry mechanism.
# This ensures that Pinecone queries are also robust against transient errors.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10),
stop=stop_after_attempt(MAX_RETRIES),
retry=retry_if_exception_type(PineconeException), # Only retry if a PineconeException occurs.
reraise=True # Re-raise the exception if all retries fail.
)
def query_pinecone_with_retry(embedding_vector, top_k_count, pinecone_filter):
"""
Performs a Pinecone index query with retry logic.
"""
return index.query(
vector=embedding_vector,
top_k=top_k_count,
include_values=False, # We don't need the actual vector values in the response.
include_metadata=False, # We don't need the metadata in the response for this logic.
filter=pinecone_filter # Apply the constructed metadata filter.
)
# Attempt to query Pinecone for redirect candidates.
try:
res = query_pinecone_with_retry(embedding, fetch_count, filt)
except PineconeException as e:
# If Pinecone query fails after retries, log the error and skip this URL.
logging.error(f"Failed to query Pinecone for {raw_url} after {MAX_RETRIES} retries: {e}")
continue
candidate = None # Initialize redirect candidate to None.
score = None # Initialize relevance score to None.
# Iterate through the Pinecone query results (matches) to find a suitable candidate.
for m in res.get("matches", ()):
cid = m.get("id") # Get the ID (URL) of the matched document in Pinecone.
# A candidate is suitable if:
# 1. It exists (cid is not None).
# 2. It's not the original URL itself (to prevent self-redirects).
# 3. It's not another URL from the input_urls set (to prevent redirecting to a page that's also being redirected).
if cid and cid != url and cid not in input_urls:
candidate = cid # Assign the first valid candidate found.
score = m.get("score") # Get the relevance score of this candidate.
break # Stop after finding the first suitable candidate (Pinecone returns by relevance).
# Append the results for the current URL to the batch.
batch.append({"URL": url, "Redirect Candidate": candidate, "Relevance Score": score})
processed += 1 # Increment the counter for processed URLs.
msg = f"Mapped {url} → {candidate}"
if score is not None:
msg += f" ({score:.4f})" # Add score to log message if available.
logging.info(msg) # Log the mapping result.
# Periodically flush the batch results to the output CSV.
if processed % LOG_BATCH_SIZE == 0:
out_df = pd.DataFrame(batch) # Convert the current batch to a DataFrame.
# Determine file mode: 'a' (append) if file exists, 'w' (write) if new.
mode="a" if os.path.exists(output_csv) else 'w'
# Determine if header should be written (only for new files).
header = not os.path.exists(output_csv)
# Write the batch to the CSV.
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
batch.clear() # Clear the batch after writing to free memory.
if not test_mode:
clear_output(wait=True) # Clear output in Jupyter for cleaner progress display.
print(f"Progress: {processed} / {total}") # Print progress update.
time.sleep(QUERY_DELAY) # Pause for a short delay to avoid overwhelming APIs.
# After the loop, write any remaining items in the batch to the output CSV.
if batch:
out_df = pd.DataFrame(batch)
mode="a" if os.path.exists(output_csv) else 'w'
header = not os.path.exists(output_csv)
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
logging.info(f"Completed. Total processed: {processed}") # Log completion message.
if __name__ == "__main__":
# This block ensures that build_redirect_map is called only when the script is executed directly.
# It passes the user-defined configuration parameters to the main function.
build_redirect_map(INPUT_CSV, OUTPUT_CSV, CANDIDATE_FETCH_COUNT, TEST_MODE)
Embora a qualidade da saída possa ser considerada satisfatória, ela fica aquém da qualidade observada com o Google Vertex AI.
Abaixo da tabela, você pode ver a diferença na qualidade da saída.
| Url | Google Vertex | Abra a IA |
| /O que é-ego/ | /Google-Eat/What-IS-It/ | /5-Things-você-pode-fazer-me-now-to-improve-your-leat-for-Google/408423/ |
| /Local-seo-for-Lawyers/ | /Lei-Firm-Seo/What-Is-Law-Firm-Seo/ | /LEGAL-SEO-CONFERRAMENTE-EXCLUSIVAMENTE-PARA-LAWYERS-SPA/528149/ |
Quando se trata de SEO, embora o Google Vertex AI seja três vezes mais caro que o modelo do OpenAI, prefiro usar o vértice.
A qualidade dos resultados é significativamente maior. Embora você possa incorrer em um custo maior por unidade de texto processada, você se beneficia da qualidade superior da saída, que economiza diretamente tempo valioso na revisão e validação dos resultados.
Pela minha experiência, custa cerca de US $ 0,04 para processar 20.000 URLs usando o Google Vertex AI.
Embora seja dito que seja mais caro, ainda é ridiculamente barato, e você não deve se preocupar se estiver lidando com tarefas envolvendo alguns milhares de URLs.
No caso de processamento de 1 milhão de URLs, o preço projetado seria de aproximadamente US $ 2.
Se você ainda deseja um método gratuito, use os modelos Bert e Llama, de abraçar o rosto para gerar incorporações de vetor sem pagar uma taxa por telefone.
O custo real vem da potência de computação necessária para executar os modelos e você deve gerar incorporações vetoriais de todos os seus artigos no Pinecone ou em qualquer outro banco de dados vetorial usando esses modelos, se você estiver consultando usando vetores gerados a partir de Bert ou Llama.
Em resumo: ai é o seu poderoso aliado
A IA permite dimensionar seus esforços de SEO ou marketing e automatizar as tarefas mais tediosas.
Isso não substitui sua experiência. Ele foi projetado para subir de nível suas habilidades e equipá -lo para enfrentar desafios com maior capacidade, tornando o processo mais envolvente e divertido.
Dominar essas ferramentas é essencial para o sucesso. Sou apaixonado por escrever sobre esse tópico para ajudar os iniciantes a aprender e se sentir inspirados.
À medida que avançamos nesta série, exploraremos como usar o Google Vertex AI para criar um plug -in interno de vincular WordPress.
Mais recursos:
Imagem em destaque: BestForBest/Shutterstock




