
Como automatizar o cluster de palavras -chave de SEO por intenção de pesquisa com Python
Há muito a saber sobre a intenção de pesquisa, desde o uso de aprendizado profundo para inferir a intenção de pesquisa, classificando o texto e quebrando os títulos do SERP usando técnicas de processamento de linguagem natural (PNL), para agrupar com base na relevância semântica, com os benefícios explicados.
Não apenas sabemos os benefícios de decifrar a intenção de pesquisa, mas também temos várias técnicas à nossa disposição de escala e automação.
Então, por que precisamos de outro artigo para automatizar a intenção de pesquisa?
A intenção de pesquisa é cada vez mais importante agora que a pesquisa de IA chegou.
Embora mais geralmente estivesse na era da pesquisa de 10 links azuis, o oposto é verdadeiro com a tecnologia de pesquisa de IA, pois essas plataformas geralmente buscam minimizar os custos de computação (por flop) para fornecer o serviço.
Os SERPs ainda contêm as melhores idéias para a intenção de pesquisa
Até agora, as técnicas envolvem fazer sua própria IA, ou seja, obtendo toda a cópia dos títulos do conteúdo de classificação para uma determinada palavra -chave e depois alimentando -a em um modelo de rede neural (que você precisa construir e testar) ou usando PNL para agrupar palavras -chave.
E se você não tiver tempo ou conhecimento para construir sua própria IA ou invocar a API da IA aberta?
Embora a similaridade de cosseno tenha sido apontada como a resposta para ajudar os profissionais de SEO a navegar na demarcação de tópicos de taxonomia e estruturas do site, ainda mantenho que o agrupamento de pesquisa pelos resultados da SERP é um método muito superior.
Isso ocorre porque a IA está muito interessada em fundamentar seus resultados em SERPs e por boas razões – é modelada nos comportamentos do usuário.
Há outra maneira de usar a IA própria do Google para fazer o trabalho para você, sem precisar raspar todo o conteúdo do SERPS e criar um modelo de IA.
Vamos supor que o Google classifique os URLs do site pela probabilidade de o conteúdo que satisfaça a consulta do usuário em ordem decrescente. Daqui resulta que, se a intenção de duas palavras -chave for a mesma, é provável que os SERPs sejam semelhantes.
Durante anos, muitos profissionais de SEO compararam os resultados do SERP para que as palavras -chave inferirem a intenção de pesquisa compartilhada (ou compartilhada) de permanecer no topo das atualizações principais, portanto isso não é novidade.
O valor agregado aqui é a automação e a escala dessa comparação, oferecendo velocidade e maior precisão.
Como agrupar palavras -chave por intenção de pesquisa em escala usando python (com código)
Supondo que você tenha seus resultados de SERPs em um download do CSV, vamos importá -lo para o seu notebook Python.
1. Importe a lista para o seu notebook Python
import pandas as pd
import numpy as np
serps_input = pd.read_csv('data/sej_serps_input.csv')
del serps_input('Unnamed: 0')
serps_input
Abaixo está o arquivo SERPS agora importado para um quadro de dados de pandas.
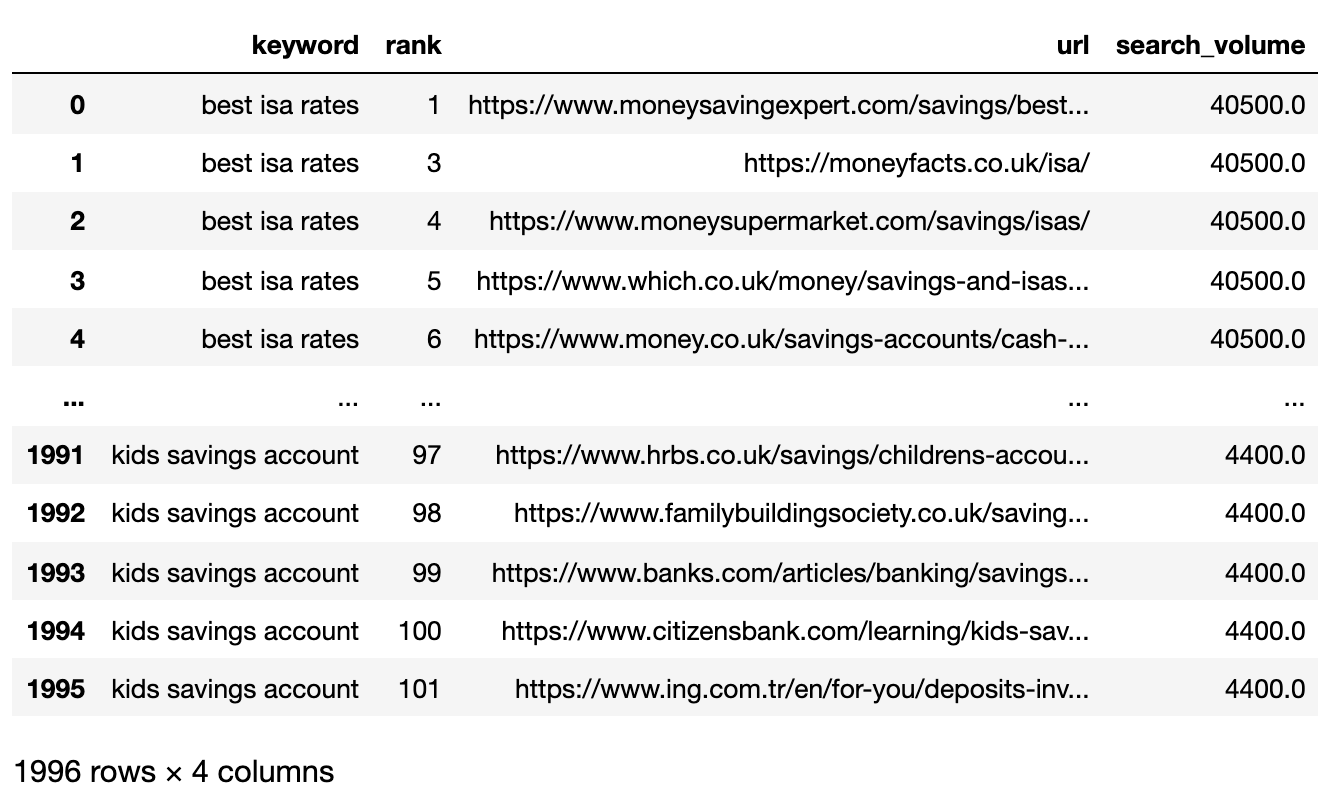 Imagem do autor, abril de 2025
Imagem do autor, abril de 20252. Dados de filtro para a página 1
Queremos comparar os resultados da página 1 de cada SERP entre palavras -chave.
Dividiremos o quadro de dados em mini -quadros de palavras -chave para executar a função de filtragem antes de recombinar em um único quadro de dados, porque queremos filtrar no nível da palavra -chave:
# Split
serps_grpby_keyword = serps_input.groupby("keyword")
k_urls = 15
# Apply Combine
def filter_k_urls(group_df):
filtered_df = group_df.loc(group_df('url').notnull())
filtered_df = filtered_df.loc(filtered_df('rank') <= k_urls)
return filtered_df
filtered_serps = serps_grpby_keyword.apply(filter_k_urls)
# Combine
## Add prefix to column names
#normed = normed.add_prefix('normed_')
# Concatenate with initial data frame
filtered_serps_df = pd.concat((filtered_serps),axis=0)
del filtered_serps_df('keyword')
filtered_serps_df = filtered_serps_df.reset_index()
del filtered_serps_df('level_1')
filtered_serps_df
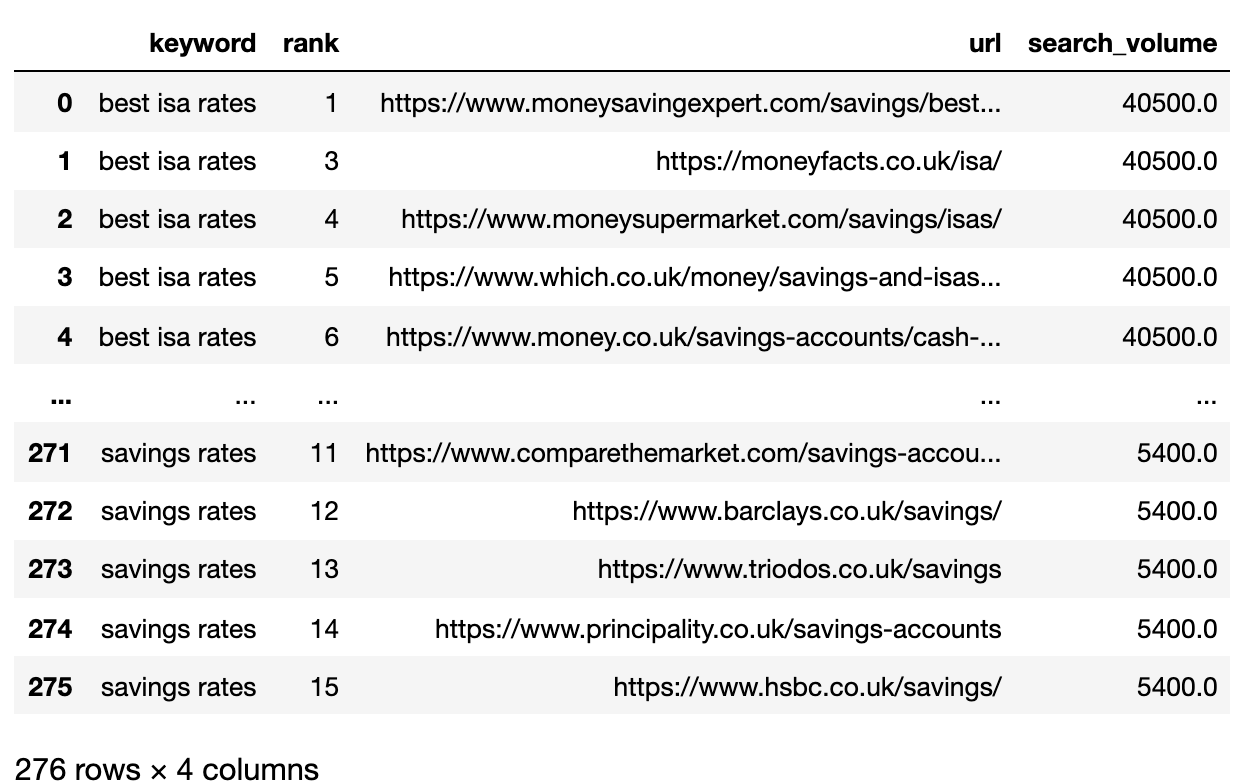 Imagem do autor, abril de 2025
Imagem do autor, abril de 20253. Convert Ranking URLs To A String
Because there are more SERP result URLs than keywords, we need to compress those URLs into a single line to represent the keyword’s SERP.
Here’s how:
# convert results to strings using Split Apply Combine
filtserps_grpby_keyword = filtered_serps_df.groupby("keyword")
def string_serps(df):
df('serp_string') = ''.join(df('url'))
return df # Combine strung_serps = filtserps_grpby_keyword.apply(string_serps)
# Concatenate with initial data frame and clean
strung_serps = pd.concat((strung_serps),axis=0)
strung_serps = strung_serps(('keyword', 'serp_string'))#.head(30)
strung_serps = strung_serps.drop_duplicates()
strung_serps
Abaixo mostra o SERP compactado em uma única linha para cada palavra -chave.
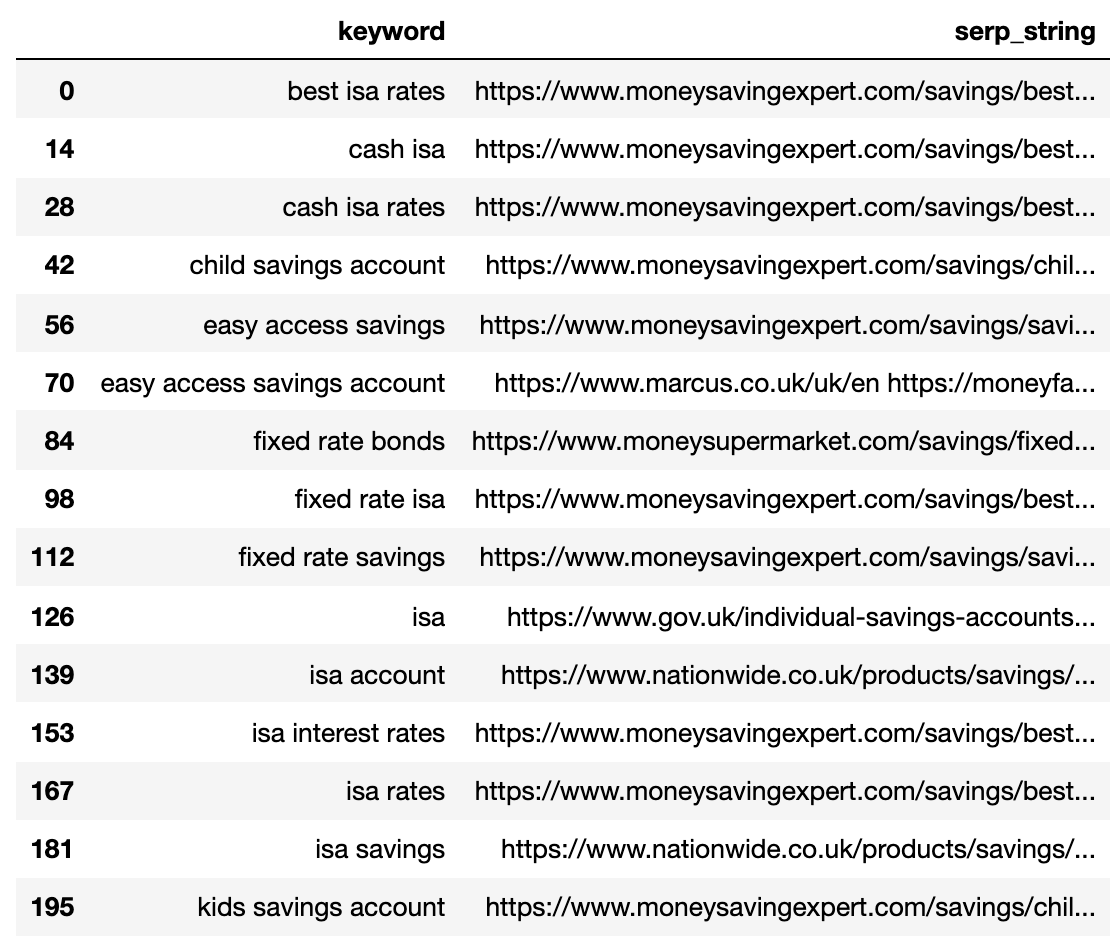 Imagem do autor, abril de 2025
Imagem do autor, abril de 20254. Compare a distância da serp
Para executar a comparação, agora precisamos de todas as combinações de SERP de palavras -chave emparelhadas com outros pares:
# align serps
def serps_align(k, df):
prime_df = df.loc(df.keyword == k)
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_a", 'keyword': 'keyword_a'})
comp_df = df.loc(df.keyword != k).reset_index(drop=True)
prime_df = prime_df.loc(prime_df.index.repeat(len(comp_df.index))).reset_index(drop=True)
prime_df = pd.concat((prime_df, comp_df), axis=1)
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_b", 'keyword': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'keyword'})
return prime_df
columns = ('keyword', 'serp_string', 'keyword_b', 'serp_string_b')
matched_serps = pd.DataFrame(columns=columns)
matched_serps = matched_serps.fillna(0)
queries = strung_serps.keyword.to_list()
for q in queries:
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
matched_serps

The above shows all of the keyword SERP pair combinations, making it ready for SERP string comparison.
There is no open-source library that compares list objects by order, so the function has been written for you below.
The function “serp_compare” compares the overlap of sites and the order of those sites between SERPs.
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Only compare the top k_urls results
def serps_similarity(serps_str1, serps_str2, k=15):
denom = k+1
norm = sum((2*(1/i - 1.0/(denom)) for i in range(1, denom)))
#use to tokenize the URLs
ws_tok = sm.WhitespaceTokenizer()
#keep only first k URLs
serps_1 = ws_tok.tokenize(serps_str1)(:k)
serps_2 = ws_tok.tokenize(serps_str2)(:k)
#get positions of matches
match = lambda a, b: (b.index(x)+1 if x in b else None for x in a)
#positions intersections of form ((pos_1, pos_2), ...)
pos_intersections = ((i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None)
pos_in1_not_in2 = (i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None)
pos_in2_not_in1 = (i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None)
a_sum = sum((abs(1/i -1/j) for i,j in pos_intersections))
b_sum = sum((abs(1/i -1/denom) for i in pos_in1_not_in2))
c_sum = sum((abs(1/i -1/denom) for i in pos_in2_not_in1))
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the function
matched_serps('si_simi') = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
# This is what you get
matched_serps(('keyword', 'keyword_b', 'si_simi'))

Now that the comparisons have been executed, we can start clustering keywords.
We will be treating any keywords that have a weighted similarity of 40% or more.
# group keywords by search intent
simi_lim = 0.4
# join search volume
keysv_df = serps_input(('keyword', 'search_volume')).drop_duplicates()
keysv_df.head()
# append topic vols
keywords_crossed_vols = serps_compared.merge(keysv_df, on = 'keyword', how = 'left')
keywords_crossed_vols = keywords_crossed_vols.rename(columns = {'keyword': 'topic', 'keyword_b': 'keyword',
'search_volume': 'topic_volume'})
# sim si_simi
keywords_crossed_vols.sort_values('topic_volume', ascending = False)
# strip NAN
keywords_filtered_nonnan = keywords_crossed_vols.dropna()
keywords_filtered_nonnan
Agora temos o nome de tópico potencial, as palavras -chave SERP similaridade e os volumes de pesquisa de cada um.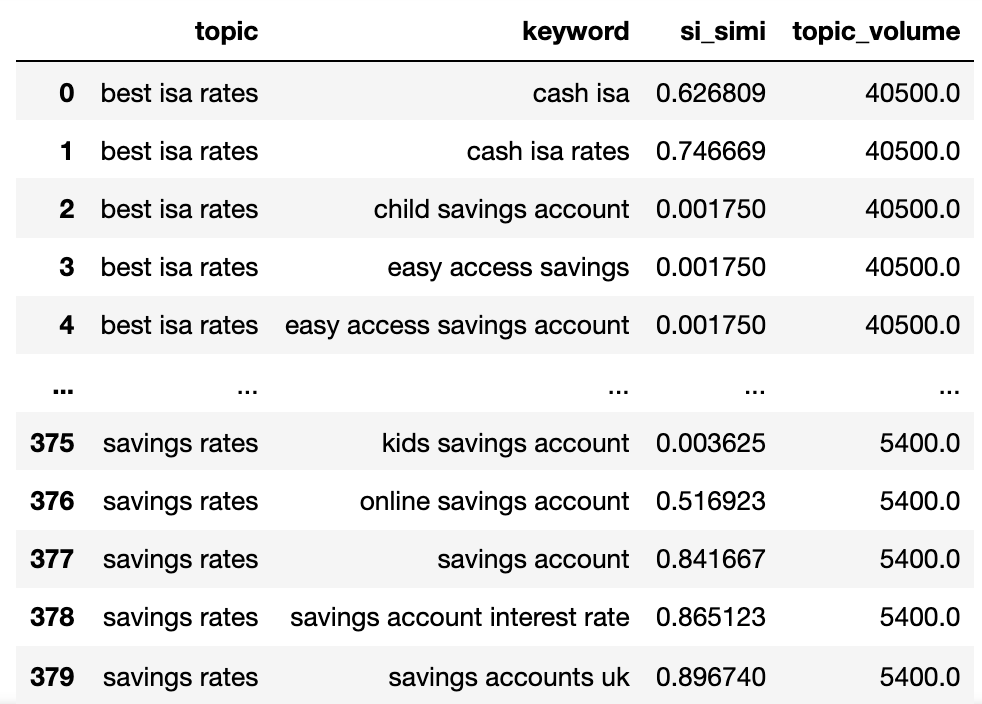
Você observará que a palavra -chave e o Keyword_B foram renomeadas para tópico e palavra -chave, respectivamente.
Agora vamos iterar sobre as colunas no quadro de dados usando a técnica Lambda.
A técnica Lambda é uma maneira eficiente de iterar sobre linhas em um quadro de dados de pandas porque converte linhas em uma lista em oposição à função .iterrows ().
Aqui vai:
queries_in_df = list(set(matched_serps('keyword').to_list()))
topic_groups = {}
def dict_key(dicto, keyo):
return keyo in dicto
def dict_values(dicto, vala):
return any(vala in val for val in dicto.values())
def what_key(dicto, vala):
for k, v in dicto.items():
if vala in v:
return k
def find_topics(si, keyw, topc):
if (si >= simi_lim):
if (not dict_key(sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, topc)):
if (not dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
sim_topic_groups(keyw) = (keyw)
sim_topic_groups(keyw) = (topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, keyw)
sim_topic_groups(d_key).append(topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (not dict_values(sim_topic_groups, keyw)) and (dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, topc)
sim_topic_groups(d_key).append(keyw)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (not topc in sim_topic_groups):
sim_topic_groups(keyw).append(topc)
sim_topic_groups(keyw).append(keyw)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (not keyw in sim_topic_groups) and (topc in sim_topic_groups):
sim_topic_groups(topc).append(keyw)
sim_topic_groups(topc).append(topc)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (topc in sim_topic_groups):
if len(sim_topic_groups(keyw)) > len(sim_topic_groups(topc)):
sim_topic_groups(keyw).append(topc)
(sim_topic_groups(keyw).append(x) for x in sim_topic_groups.get(topc))
sim_topic_groups.pop(topc)
elif len(sim_topic_groups(keyw)) < len(sim_topic_groups(topc)):
sim_topic_groups(topc).append(keyw)
(sim_topic_groups(topc).append(x) for x in sim_topic_groups.get(keyw))
sim_topic_groups.pop(keyw)
elif len(sim_topic_groups(keyw)) == len(sim_topic_groups(topc)):
if sim_topic_groups(keyw) == topc and sim_topic_groups(topc) == keyw:
sim_topic_groups.pop(keyw)
elif si < simi_lim:
if (not dict_key(non_sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups,keyw)):
non_sim_topic_groups(keyw) = (keyw)
if (not dict_key(non_sim_topic_groups, topc)) and (not dict_key(sim_topic_groups, topc)) and (not dict_values(sim_topic_groups,topc)):
non_sim_topic_groups(topc) = (topc)
Abaixo mostra um dicionário que contém todas as palavras -chave agrupadas pela intenção de pesquisa em grupos numerados:
{1: ('fixed rate isa',
'isa rates',
'isa interest rates',
'best isa rates',
'cash isa',
'cash isa rates'),
2: ('child savings account', 'kids savings account'),
3: ('savings account',
'savings account interest rate',
'savings rates',
'fixed rate savings',
'easy access savings',
'fixed rate bonds',
'online savings account',
'easy access savings account',
'savings accounts uk'),
4: ('isa account', 'isa', 'isa savings')}Vamos enfiar isso em um DataFrame:
topic_groups_lst = ()
for k, l in topic_groups_numbered.items():
for v in l:
topic_groups_lst.append((k, v))
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=('topic_group_no', 'keyword'))
topic_groups_dictdf
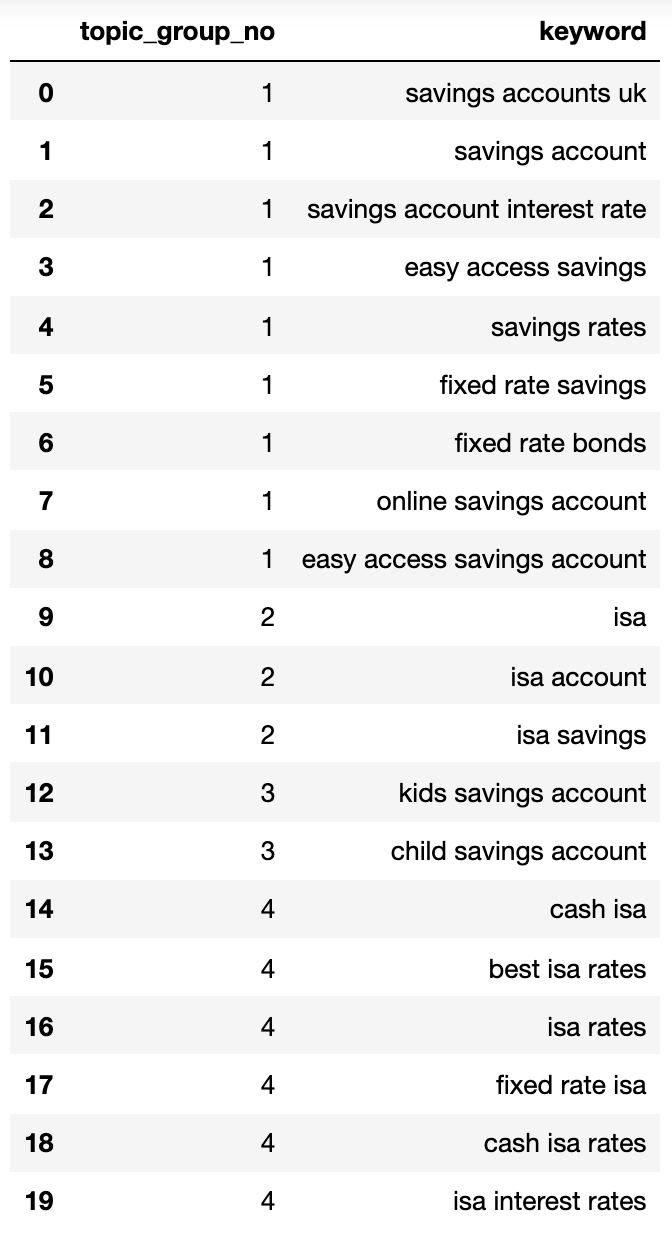 Imagem do autor, abril de 2025
Imagem do autor, abril de 2025Os grupos de intenção de pesquisa acima mostram uma boa aproximação das palavras -chave dentro deles, algo que um especialista em SEO provavelmente alcançaria.
Embora tenhamos usado apenas um pequeno conjunto de palavras -chave, o método pode obviamente ser escalado para milhares (se não mais).
Ativando as saídas para melhorar sua pesquisa
Obviamente, o exposto acima pode ser levado ainda mais usando redes neurais, processando o conteúdo do ranking para clusters mais precisos e nomeação de grupos de cluster, como alguns dos produtos comerciais já o fazem.
Por enquanto, com esta saída, você pode:
- Incorpore isso aos seus próprios sistemas de painel de SEO para tornar suas tendências e SEO relatando mais significativos.
- Crie melhores campanhas de pesquisa pagas, estruturando suas contas do Google Ads por busca de uma pontuação de maior qualidade.
- Mesclar URLs redundantes de pesquisa de comércio eletrônico de faceta.
- Estruture a taxonomia de um site de compras de acordo com a intenção de pesquisa, em vez de um catálogo típico de produtos.
Tenho certeza de que há mais aplicativos que não mencionei – sinta -se à vontade para comentar sobre os importantes que eu ainda não mencionei.
De qualquer forma, sua pesquisa de palavras -chave SEO ficou um pouco mais escalável, precisa e mais rápida!
Faça o download do código completo aqui para seu próprio uso.
Mais recursos:
Imagem em destaque: Buch and Bee/Shutterstock



 (2025)")
:max_bytes(150000):strip_icc()/4547290-6a5633c323464ea0a39d94d9c5851cb7.jpg?w=768&resize=768,0&ssl=1 "15 jantares de frango com baixo teor de carboidratos, rápidos e deliciosos, em menos de 30 minutos – StylePersuit")
